Votre code CUDA peut-il tourner sur tous les GPUs ?

Aujourd’hui, les GPUs (Graphic Processing Units) sont présentés comme les puces qui rendent l’Intelligence Artificielle (IA) possible. Mais, pendant longtemps, ces puces ont surtout intéressé les gamers et les développeurs de jeux vidéo. En effet, elles ont été conçues à l’origine pour effectuer efficacement le rendu graphique sophistiqué attendu des jeux modernes.
Le lien entre ces deux univers n’a rien d’évident. Pourtant, il existe de nombreuses similitudes entre les calculs nécessaires au rendu 3D et ceux impliqués dans une conversation avec un LLM (Large Language Model). Résultat : la demande croissante en capacité de calcul pour l’IA a fait migrer les GPU haut de gamme des PC de jeu vers les datacenters.
Les GPU sont des composants puissants, mais ils nécessitent un environnement de développement spécifique. Aujourd’hui, CUDA est l’environnement de programmation GPU le plus populaire pour les applications non graphiques. C’est un écosystème riche, largement adopté grâce à son ergonomie, la richesse de ses outils et bibliothèques, et une vaste communauté de développeurs.
Cependant, il reste fondamentalement lié au matériel NVIDIA. Ce qui est plutôt regrettable, car de nombreux autres constructeurs — le plus notable étant AMD — proposent eux aussi des solutions matérielles intéressantes. On peut donc légitimement se demander : est-il possible d’exécuter du code CUDA sur tous les GPUs ?
Dans cet article, nous brossons un panorama du monde du General Purpose GPU (GPGPU), des débuts de CUDA jusqu’aux alternatives disponibles aujourd’hui.
Les débuts de la programmation GPU
En 1999, NVIDIA lançait ce qu’il présentait comme le premier GPU : le GeForce 256. C’était la première puce capable de gérer l’ensemble du pipeline graphique — les différentes étapes nécessaires pour transformer une scène en image affichable.
Avant cela, les étapes de transformation (mouvements d’objets, changements de repère) et d’éclairage étaient assurées par le CPU (Central Processing Unit). Ces opérations, très coûteuses en ressources et en temps, exigeaient une grande ingéniosité de la part des développeurs de jeux — à cet égard, Doom était un chef-d’œuvre de code. NVIDIA a levé cette contrainte en introduisant des unités de transformation et d’éclairage (T&L) capables d’exécuter ces opérations directement dans le matériel.
Le GeForce 256 ne se contentait pas de décharger le CPU : il exécutait ces opérations 2 à 4 fois plus vite. Cela ne signifie pas pour autant que les GPU sont fondamentalement « meilleurs » que les CPU, mais simplement qu’ils excellent dans ce type de tâche.
Cela tient au fait que les deux reposent sur des logiques de calcul différentes. Les CPU utilisent le parallélisme d’instructions (pipelining) : différentes unités matérielles opèrent simultanément sur des données distinctes — pendant qu’une instruction est récupérée depuis la mémoire de programme, une autre est décodée, une troisième exécutée, etc. Ce degré de parallélisme reste limité, mais cette approche convient à des séquences complexes d’opérations. Les GPU, eux, reposent sur le parallélisme de données (data parallelism), qui leur permet d’exécuter la même opération sur un grand nombre de données en parallèle — par exemple, calculer la couleur de tous les pixels d’un écran simultanément.
Lorsque les développeurs ont compris que ce parallélisme massif pouvait être utile au-delà du graphisme, ils ont commencé à détourner les GPU pour faire de la programmation plus générale (General-purpose processing on graphics processing units, ou GPGPU). Mais à ses débuts, la GPGPU n’avait rien de simple : dans la deuxième édition de GPU GEMS (2005), NVIDIA expliquait par exemple comment utiliser les unités dites “Vertex Processor” et “Fragment Processor” — normalement dédiés au rendu de textures — pour effectuer des calculs généraux, comme des algorithmes de tri.
Autant dire que les débuts de la GPGPU étaient loin d’être faciles. Heureusement, plusieurs environnements de programmation sont venus simplifier les choses au fil du temps. Explorons-les un par un.
CUDA
En 2007, NVIDIA lançait CUDA : un environnement GPGPU entièrement intégré, tirant parti de la programmabilité accrue de l’architecture GeForce 8. Fortement inspiré de BrookGPU — une première tentative académique menée à Stanford —, CUDA s’est rapidement imposé car il est gratuit et facile à utiliser, et fonctionne sur toute la gamme NVIDIA, des cartes d’entrée de gamme aux GPU de datacenter les plus puissants.
Le cœur de CUDA repose sur une légère extension du C++ permettant de programmer aisément des GPU. Cette extension permet d’écrire des programmes hétérogènes — c'est-à-dire utilisant à la fois CPU et GPU — dans un même fichier source, tout en simplifiant considérablement la gestion du GPU.
Par ailleurs, le framework CUDA est extrêmement complet. Aujourd’hui, il inclut :
- une extension du langage — principalement C++, avec des wrappers pour Python et Fortran ;
- un compilateur, le NVIDIA CUDA Compiler (NVCC), qui convertit le code source en fat binaries contenant le code machine pour le CPU et en code PTX (Parallel Thread eXecution) pour le GPU ;
- un ensemble d’outils pour le débogage et le profilage ;
- une large collection de librairies (plus de 400), couvrant l’algèbre linéaire (BLAS), le calcul scientifique (FFT), la communication (NVSHMEM, NCCL), et plus récemment les réseaux de neurones (cuDNN).
HIP
Depuis le rachat d’ATI Technologies en 2006, Advanced Micro Devices (AMD) est le principal concurrent de NVIDIA sur le marché du GPU. Dix ans après la sortie de CUDA, AMD lançait ROCm (Radeon Open Compute), sa propre pile logicielle pour GPU. Contrairement à CUDA, une grande partie de ROCm est open source.
L’environnement ROCm présente de nombreuses similitudes avec CUDA. La raison ? CUDA est devenu si populaire qu’il a fini par imposer les standards de productivité attendus d’un environnement GPGPU. Ainsi, HIP (Heterogeneous-computing Interface for Portability), le modèle de programmation de ROCm, a été conçu pour être hautement interopérable avec CUDA, comme illustré ci-dessous.
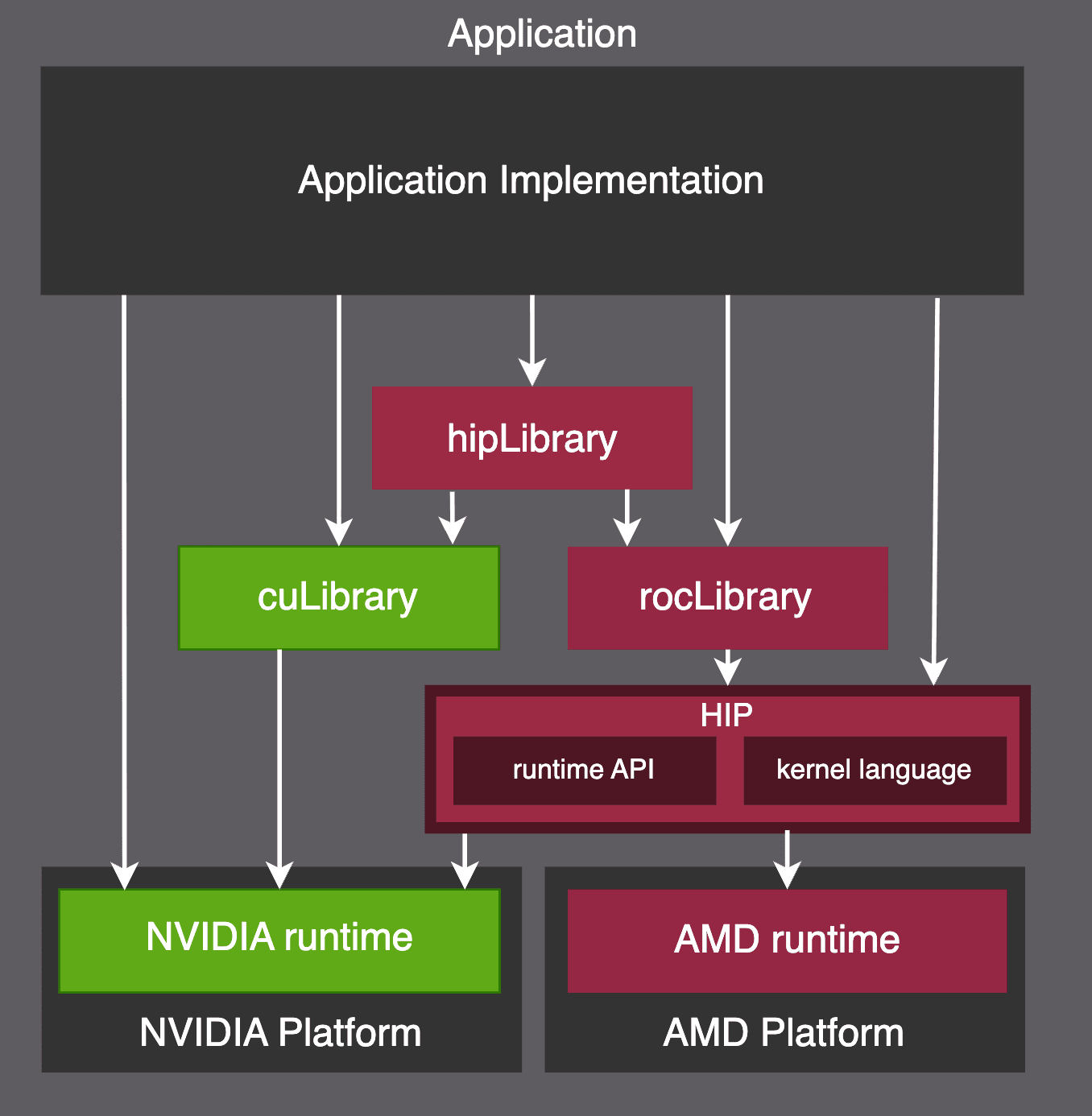
HIP est fonctionnellement équivalent à CUDA, et AMD propose des outils pour faciliter la migration d’un code CUDA vers l’environnement ROCm. L’un des outils clés est HIPIFY, qui transpile le code CUDA en son équivalent HIP. Le portage peut être extrêmement direct : par exemple, l’appel cudaGetDevice() devient simplement hipGetDevice() par substitution de texte. Le backend ROCm de PyTorch est d’ailleurs généré automatiquement à partir du code CUDA via HIPIFY.
Une API pour les gouverner toutes ?
Les outils HIPIFY d’AMD peuvent convertir la majorité du code CUDA vers HIP, mais cette interopérabilité a ses limites. Les fonctionnalités spécifiques à l’architecture, comme le code PTX (le langage d’assemblage virtuel de NVIDIA) inliné, doivent toujours être portées manuellement.
Pour dépasser ces limites, une équipe de Spectral Compute a dévoilé en juillet 2024 la première bêta publique de SCALE, un nouveau compilateur visant à traduire 100% du code CUDA vers du code “HIP-compatible”. À ce jour — version 1.4.2, sortie en octobre 2025 —, seules les GPU AMD sont prises en charge, mais l’objectif est de supporter à terme tout type d’accélérateur matériel.
SCALE fonctionne avec un environnement virtuel appelé scalenv qui surcharge nvcc, rendant le processus de compilation transparent pour l’utilisateur. Cependant, la chaîne de compilation ne prend pas encore en charge suffisamment d’APIs CUDA pour permettre le portage de frameworks majeurs comme PyTorch. Une liste des logiciels tiers compatibles est disponible sur GitHub.
Tandis que des outils de conversion comme HIPIFY et SCALE nécessitent de recompiler le code CUDA, ZLUDA adopte une autre approche : elle agit directement sur le binaire produit par nvcc. Cette solution a deux avantages : elle ne requiert pas le code source et n’exige donc aucune recompilation, tout en bénéficiant des optimisations de nvcc.
Lancé chez Intel en 2020 et repris par AMD deux ans plus tard, ZLUDA est désormais maintenu par deux développeurs indépendants. Sa dernière version (v5, octobre 2025) est encore loin de couvrir tous les cas, mais affirme pouvoir exécuter llama.cpp — une avancée notable quand la version 4 ne supportait qu’un benchmark (Geekbench 5). Le projet pourrait toutefois rencontrer des obstacles juridiques : la licence CUDA semble interdire toute tentative de traduction du code généré par le SDK CUDA vers une plateforme non-NVIDIA.
La Chine : de nouveaux GPU en pleine émergence
Ces dernières années, la Chine est devenue un acteur majeur du développement de l’IA, avec un écosystème technologique florissant. Des noms comme Moore Threads, Hygon, Ascend, KunlunXin, Enflame ou Cambricon ne vous disent peut-être rien, mais ils font partie de la myriade de nouveaux fabricants de GPU — souvent soutenus par les géants chinois de la tech — qui s’attaquent pour le moment seulement au marché intérieur chinois.
La plupart de ces acteurs restent de taille modeste, mais leur croissance devrait s’accélérer, d’autant que le gouvernement chinois a interdit en septembre 2025 l’usage des puces NVIDIA pour les applications d’IA au profit des fournisseurs locaux. Tous ces fabricants développent leurs propres piles logicielles, souvent largement inspirées de CUDA. Certains — comme Huawei avec son modèle phare 910C — revendiquent même une compatibilité native avec CUDA.
Ces solutions ne sont pas encore répandues hors de Chine, mais elles pourraient bien le devenir.
Vers un écosystème plus large
CUDA est aujourd’hui la plateforme de référence pour l’accélération GPU, mais elle reste limitée au matériel NVIDIA. Il existe toutefois plusieurs façons de convertir ce code afin qu’il s’exécute sur des GPU AMD. Ces outils n’ont pas tous atteint le même degré de maturité mais ils tendent tous vers une compatibilité complète à terme. Parallèlement, de nouveaux fournisseurs de GPU — notamment en Chine — traitent l’hégémonie CUDA comme un fait établi et développent directement leurs outils autour de ce langage. En somme, le spectre du matériel « CUDA-compatible » semble appelé à s’élargir — une excellente nouvelle pour tous les développeurs.