
Eight essentials to make your account's security a priority
Security is and will always be a two-way street: it requires effort from both the user and the platform. Learn best practices to secure your account.

On February 22nd, we activated IAM for all Scaleway organizations. Identity and Access Management (IAM) is a security framework to control the authentication and authorization of individuals and manage their access to resources.
IAM is no small task; at Scaleway, every API call goes through IAM before being executed. For each second you spend reading this post, about a thousand permission requests are executed on IAM.
But here’s the thing, on February 22nd, IAM had already been live for eight months. You just didn’t know it. How did we manage to migrate so seamlessly? That’s what we will look at in this series of two blog posts.
In this first part, we’ll dive into the history of IAM at Scaleway and the different database implementations we used over the years. The second post will go further into the technical details of the migration itself.
IAM can be summarized with the question “who can access what?”. The answer to this question is determined in what we call a policy. The “who” often defines the identity: an individual, a team, or even non-human users. The “what” defines different levels of granularity we want to give access to: an organization, a project, or a particular resource.
The list of “who” or “what” in a policy depends on the business you run. Let’s have a look at these two example policies:

Even though both are valid policies, the first one is much simpler to understand and implement. In a nutshell, the policy dilemma is that you have to weigh simplicity vs. granularity.
Scaleway started in 2015 as an internal startup within Online SAS. At the time, IAM was not called IAM yet. Instead, we would refer to it as the “permissions system,” which was very simple: a user has many permissions.
Disclaimer: database models shown in this blog post are not exhaustive.
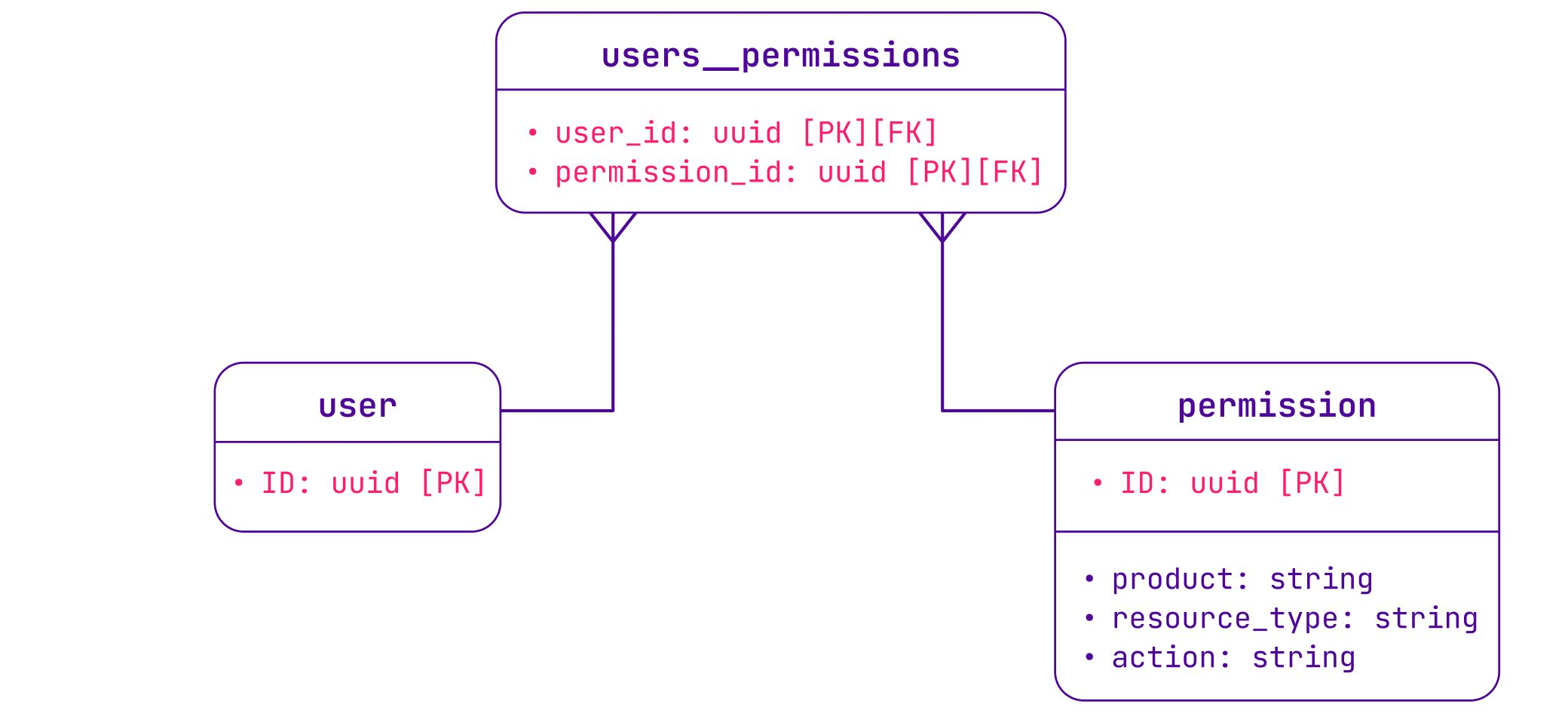
A permission represents an action to perform on a resource in a product. For example, the permission instance:server:read allows a user to read information about servers in their organization, but it does not allow them to create servers. The permission is then checked by the product API managing this resource.
This approach worked well for many years, but it had its limits:
users__permissions table.users__permissions table.As Scaleway grew, more permissions were added for new products, and a lot of new users joined Scaleway. At some point, it took a full day to seed a new permission in the database. We had clearly hit the limits of the permissions model.
We improved the performance of the permissions model by introducing permission sets — sets of one or multiple permissions that we can attribute to one or many users. We took this refactoring opportunity to introduce a Role-Based Access Control (RBAC) model: when a user assumes a role in an organization, they get access to various permission sets.
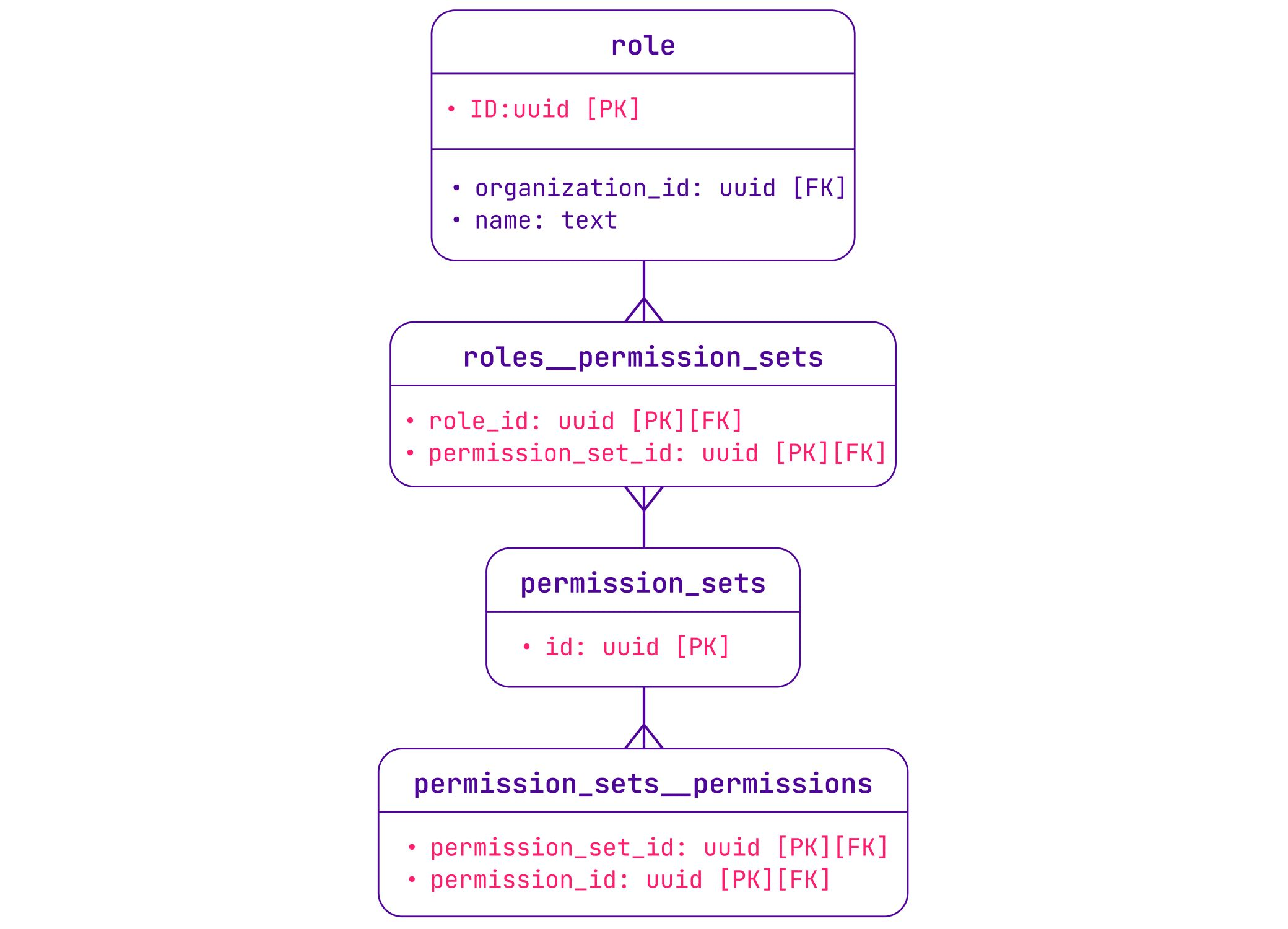
At the time, organizations equaled users, so each organization could only have one user. The idea with RBAC was to enable a multi-user feature by letting a user assume one of the four predefined roles in any organization:
In this system, users could be part of many organizations, but they remained global across Scaleway. It was a simple approach but meant that an organization owner couldn’t take actions on their users other than removing them from an organization. Example: the owner of an organization cannot enforce multi-factor authentication on their users.
In 2020, we also introduced a new feature: projects. This feature allows you to organize resources by isolating them in projects. Implementing this into our RBAC model was trivial: instead of assigning a role in an organization, we now assign it within a project.
With this feature, we also introduced project-scoped API keys. Before, API keys were bound to a global user, which means the same API key had the permissions associated with the user across all the organizations the user belongs to. With project-scoped API keys, the API key is bound to a certain role on a particular project. This was a big step toward adding more granularity to our policies.
Before:

After:

The project feature was a quick win, but we knew the RBAC model would be limited when it came to defining scope when accessing a product. We identified four possible scopes to configure access to a product:
Every time we tried to address these four use cases with RBAC, we ended up twisting the model in a way that didn’t satisfy us. But having more granularities in IAM is the top feature requested by our users, and we have great plans for IAM, such as adding granularity at the resource level and more. We didn’t want to make a compromise here, so we needed a new approach with better handling of project and organization scopes.
In 2022, we started working on our IAM system as it exists today. The main requirements were:
The first thing we did was to analyze many existing IAM systems, especially from the open-source world. None of the existing systems addressed our needs 100%. Sometimes the UX was too complicated. In other cases, the “project” concept did not exist. Most of the time, we would disagree with implementation details. The truth is, only rarely will an open-source software magically fit your business.
So we started designing our own solution by defining the list of “who” — often referred to as the principal — and the list of “what.”
There might be more in the future, but for now, we identified three use cases of principals at Scaleway: IAM user, IAM application, and IAM group.
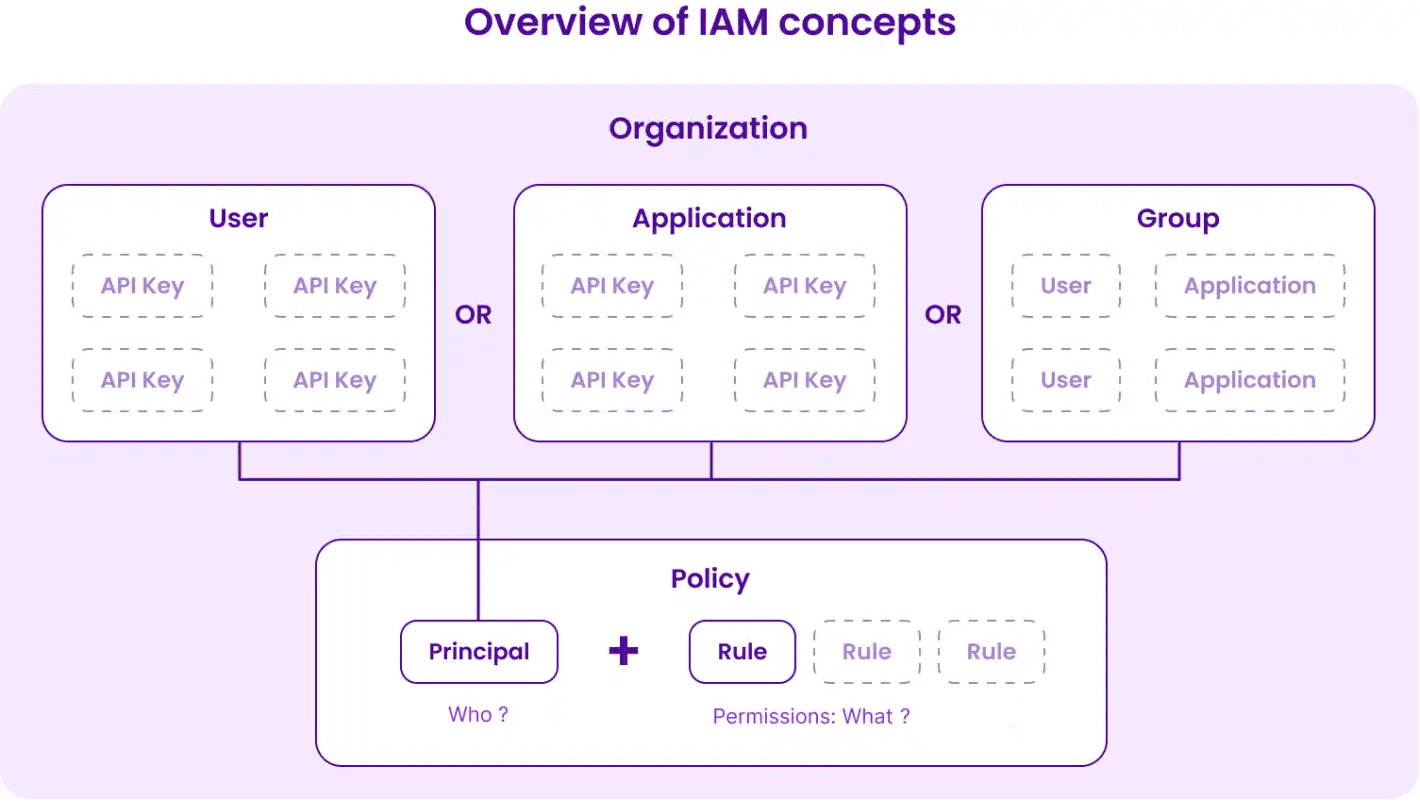
Then we defined the “what” by a series of rules that give access to permission sets on a scope:
Rules hold the granularity definitions of IAM and are the most difficult part of IAM to explain and use. So very early on, we focused on the user experience in the console and Terraform to make it easier for users to understand.
Most Scaleway users use infrastructure-as-code tools to deploy their infrastructure, the most popular being Terraform. So we decided very early on to base our design of the IAM system on what it would be like to define a policy in this particular tool. After a couple of iterations, we arrived at the following setup:
resource scaleway_iam_policy "object_storage_and_billing" { description = "gives read only access to object storage in project A and full access to billing" // Who user_id = scaleway_iam_user.alice.id // What rule { project_ids = [scaleway_account_project.my_project_a.id] permission_set_names = ["ObjectStorageReadOnly", "RedisReadOnly"] } rule { organization_id = data.scaleway_account_organization.my_orga.id permission_set_names = ["BillingFullAccess"] }}We noticed many small details, such as:
user_id, application_id, group_id — is more comprehensible than using a single attribute principal_id.These kinds of details helped us design a better API and database model.
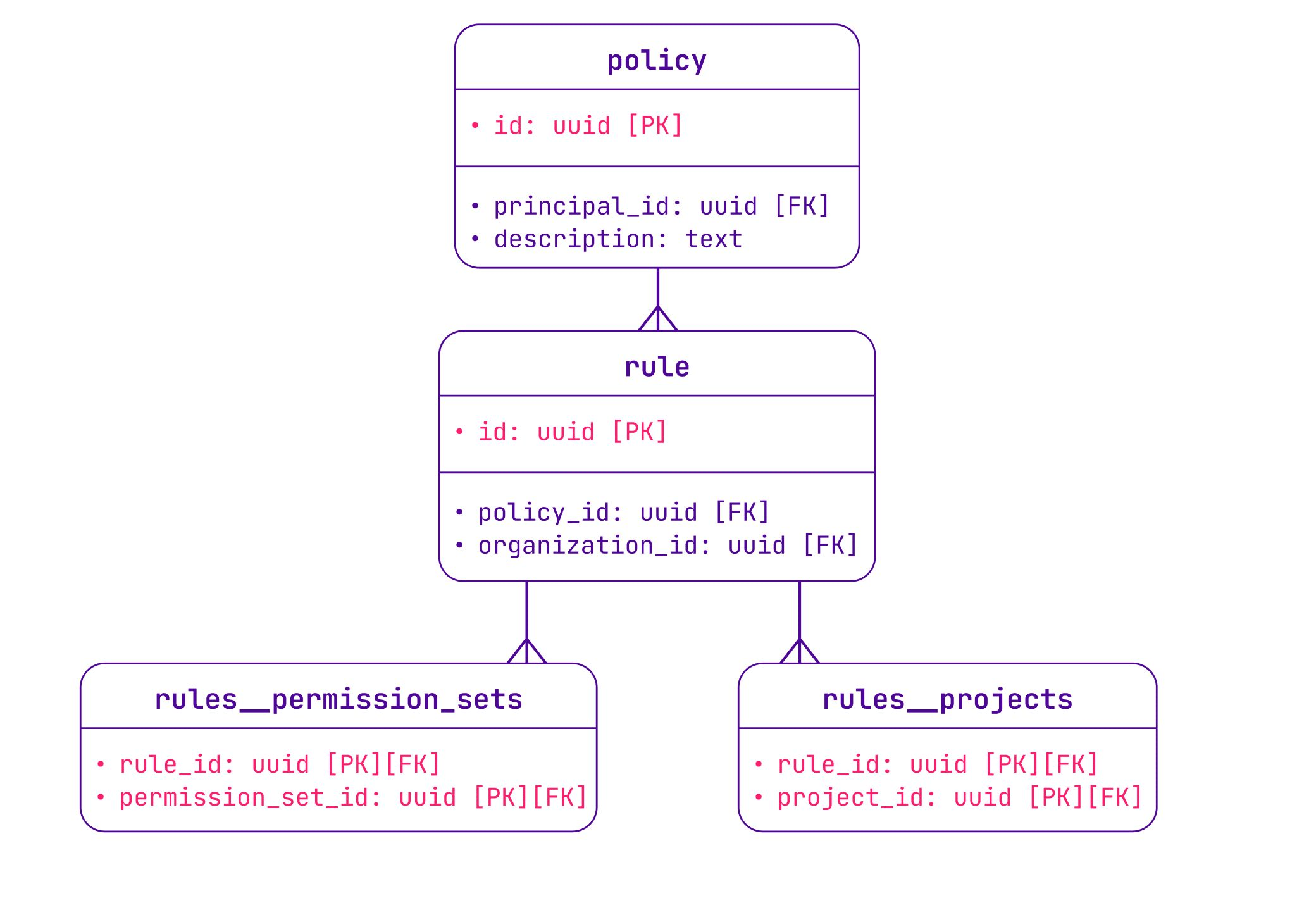
In the database, a policy is a list of IAM rules attached to a principal. Each rule allows access to a scope (project_id, organization_id) on one or multiple permission sets — all the same as in Terraform.
While designing this data model, we also tested its evolutivity against future features we plan to add to the IAM policy, such as resource-level scope, deny rules, conditions, resource principal, etc.
We have clear plans on how to implement each of them, and if you want to help us prioritize which feature is more important to you, please upvote or create a new feature request for it.
So now you know how we designed the IAM policy with a compromise between user needs and user experience, using the Terraform representation as a source of inspiration. If you want to know more about these topics, we discussed them on a Dev’Obs episode (French podcast).
You might have noticed that the new IAM concepts are quite different from the previous role-based access control. Principal, policy, group,… many of these data were nonexistent in the previous model. And the permissions API is one of our busiest internal APIs, with thousands of requests per second.
So how did we manage to completely flip the model with no downtimes? Stay tuned! All of this will be revealed in the next blog post. :-)
Security is and will always be a two-way street: it requires effort from both the user and the platform. Learn best practices to secure your account.

If you want to quickly and easily set up a cloud infrastructure, one of the best ways to do it is to create a Terraform repository. Learn the basics to start your infrastructure on Terraform.

Administering a Kubernetes cluster safely and efficiently is hard. Here's how to ensure it knows who people trying to access it are, and how to make them prove their identity