When I arrived at Scaleway a few months ago as the first Data Scientist of the company, my goal was clear: transform the company. Yes, that’s challenging! I had to have a plan and to seek for quick added value to impulse this transformation. So we got started with our first project: build a Scaler Assistant to answer all HR related questions from Scalers. Let’s see what I did to build and deploy a RAG system in one month and the tips I can give you to achieve the same.
Think small, be efficient, fail fast
Think small, be efficient, fail fast. These are the three things I told myself to keep in mind if I wanted this project to succeed.
Think small: My goal is to help Scalers to find accurate HR related information, not every single piece of information contained in the internal documentation of the company. Therefore, my RAG system should and must be tailor-made for this kind of information. No need to set up a general retrieval system that works for every kind of data, no need to go into lots of technical considerations regarding LLMs or RAG architectures.
Be efficient: I have significant experience working with LLMs, creating RAG systems and more generally doing data science, so let’s leverage everything I’ve learned so far! My plan was to go into techniques I don’t know (or even worse: research papers!) only if my personal toolbox failed. To make it clear, I am not saying that I should not try to learn new skills or explore new techniques (I love doing this and I think that it is so important to stay on track and to enjoy my job), I am saying that it takes time. My goal here is to be as efficient as I can, to deliver the project within a month, to start transforming Scaleway as soon as I can. With this in mind I chose to focus on what I know. I chose to trust myself. When this project will be running and used by many Scalers, I will take the time to improve it with newer techniques and to improve my skills at the same time. That being said, regarding the tech stack I chose for the main components of my app:
- Llama index to build my RAG system since I know this framework pretty well. It is a framework used to ease the creation of LLM-powered applications and it is really powerful when working with RAG given all the documentation management system and the myriad of retrieval techniques, data reader, preprocessing and postprocessing techniques it offers. If you are curious about it, check llama index github here
- FastAPI for API development as I am used to using this framework.
- Open WebUI for the user interface as it provides a familiar interface for the user and it comes with a lot of pre-built features, saving me a lot of time.
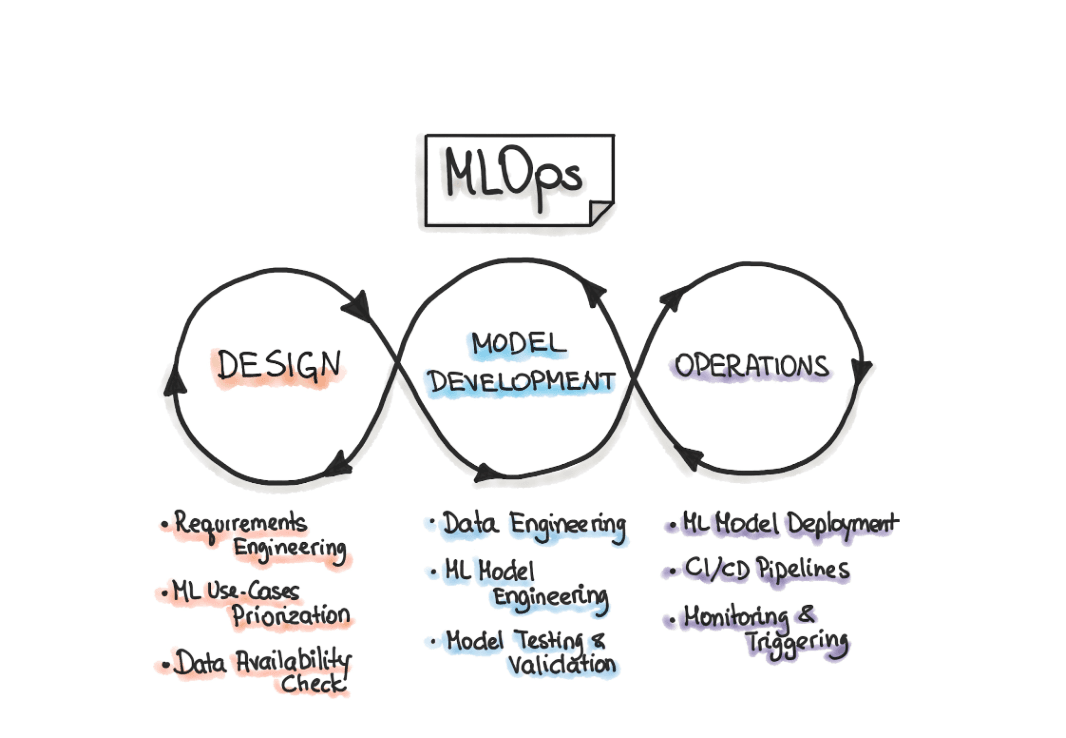
Fail fast: This may be the most important tip I could give you. There is nothing worse than working on a project, experimenting, exploring, and at the time you want to deploy it in a production environment it does not work as expected. That’s disappointing and that’s a huge waste of time. So, as soon as I had something running (even an extremely simple system) I put myself in a production-like environment. What does it mean? I containerized everything (even at the project’s early stage), orchestrated containers, made sure my containers could communicate safely, built my API endpoints at the same time I developed the system, … This philosophy is usually referred to as MLOPs cycle.
No overkilling needed, of course, just making sure that your production environment evolves at the same pace as your code. Trust me, it will save you a huge amount of time in the end!
Delivering fast is obviously a good point but to really help Scalers and to achieve my goal, performance was key. There were several areas where performance was needed such as documents retrieval accuracy, LLM response and hallucination reduction, system latency and hardware considerations for instance.
This can be a lot to work on at the same time and become quite intense. Here are some things I did to save me some time and to help me be more focused on the areas quoted previously.
Make good use of what your company offers. Lucky me, Scaleway is a cloud-provider and even provides AI products (no RAG as a service though)! It would be a shame not to use them, right? Indeed, the first thing I did was to understand what my company already provides or not. There is no need to reinvent the wheel, no need to spend time configuring database accesses, provisioning GPUs/CPUs, setting up an inference engine on a GPU if there already is a team dedicated to it … I leveraged my environment and my ecosystem. What does it mean in practice?
- I used the Generative APIs product from Scaleway. It provides API access to multiple LLMs like language models, code models, vision models or embedding ones. This came really handy for this project as I needed to use embedding and text models. Within a couple of minutes I was able to query a Llama 3.1 70B and embed my document base by making API requests! If you have ever set up LLMs on a GPU using any inference engine, you know how complicated it can become especially when you want to scale things up, balance the load in input or optimize your latency and throughput.
- I worked with internal teams to get CPU infrastructures and vector databases provisioned on our internal network. As you will see later in this article, security concerns are central to the success of the Scaler’s assistant deployment. Therefore, I needed all my infrastructure to be available on Scaleway’s internal network without any access to the public network (except to send requests to the Generative APIs product load balancer of course). At Scaleway we have teams dedicated to the provisioning and maintenance of all kinds of infrastructure you could need, so I specified my needs and they got me a vector database and a VM to start working!
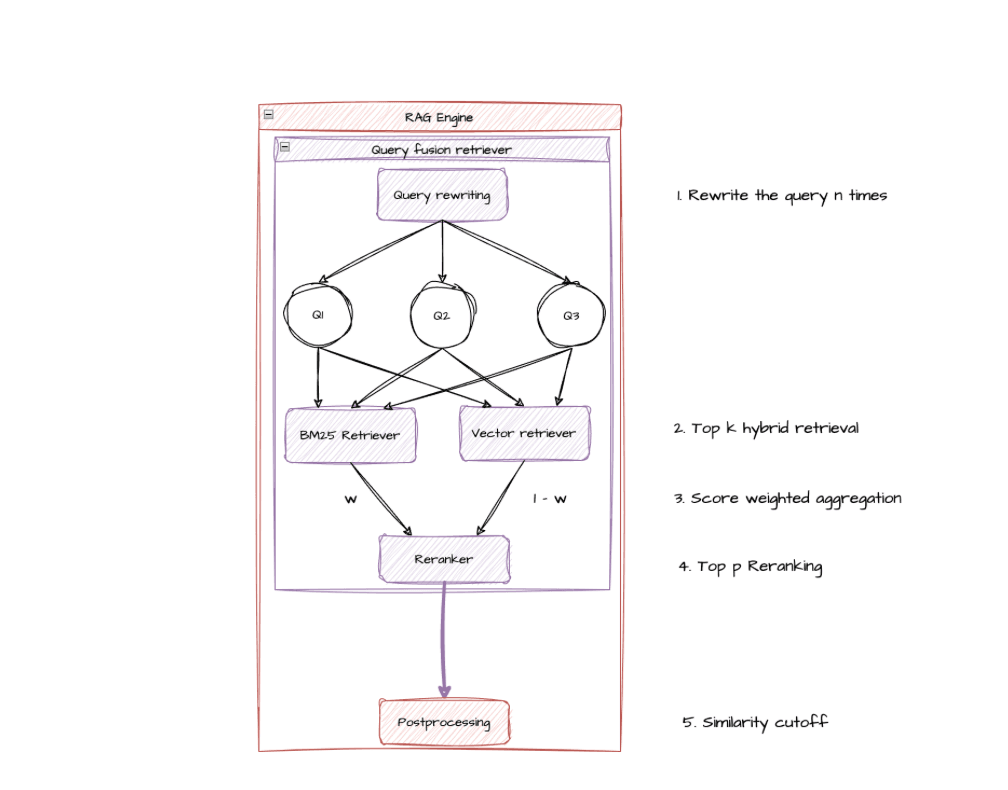
Set up a good and reproducible experimentation lab. Let’s dive into the core of the project (and the driver for performance as said before): the retrieval system. Any RAG project is useless if the document retrieval system is not accurate enough. I needed to be able to experiment and iterate on the conception of the perfect retriever for my HR related documents. But before getting my hands dirty, I had to specify my working environment, the metrics I will follow and try to improve, and most importantly when to stop experimenting. As you may know there exists many open source tools to track your experiments, some specific to RAG systems, others more general about LLMs. I chose to use neither of them. Why’s that? First, I didn’t want to spend time setting up a tool that I was maybe going to use for only a few hours (I had good hopes to come up with a performant retriever in a matter of hours, a day maximum). Second, I was not going to look at dozens of metrics at the same time nor try several embedding models, embedding dimensions or even many retriever architectures. My parameters research space was the following:
-Three retriever architectures:
-vector search retriever
-keyword search retriever
-fusion retriever (combination of vector search and keyword search retrievers)
-Similarity cutoff parameter (0 to 1 range)
-Top k for retriever
-Top p for reranker
The idea behind my choice of not using any open source experiment tracking solution was that since the HR documents were well formatted, bilingual (English and French), cleaned and regularly updated, a simple retriever combined with a basic reranker would probably perform pretty well. So I chose to only explore a couple of optimizations and to further optimize later on if needed.
Don’t overcomplicate things. Creating a performant RAG does not necessarily mean creating the best performing RAG on earth. What I mean is to well define your performance metrics, your “that’s enough” threshold, so you keep things as simple as they can. It is really tempting to always add an extra layer of postprocessing, use a more sophisticated reranker, or even define your own similarity metric for vector search but think about the marginal gain it will lead to. From my experience, the performance increase you get by complicating things is easily offset by the time you are taking to implement them and to maintain them in the future. So, keep things as simple as it can be. If your target was to get a Hit Rate of 0.91 stop as soon as you reach it. Don’t spend a day tweaking your system and to complexify your code only to reach 0.93 in the end.
Anticipate hurdles
Finally, thinking a few steps ahead and anticipating potential hurdles to the project deployment was key. For this project I was mainly concerned about security and GDPR compliance. Indeed, the whole point of the Scaler Assistant was to allow Scalers to freely chat with the system in a confidential manner regarding HR topics and of course avoid data leaks of Scaleway’s internal documentation. Not anticipating these subjects could lead to a slower deployment of the chatbot in the end or even to a hard stop of the project if it did not comply with the security and legal requirements.
Work hand to hand with security and legal teams. I am no cybersecurity expert and even less a GDPR one so I had to rely on skilled coworkers at Scaleway to anticipate the risks associated with the project. Instead of coding alone, getting to the MVP stage and then meeting with the relevant teams to ask for their approval, I decided to get in touch with them at the start of the project. I first started to design a simple architecture schema to explain how it was supposed to work, defined the purpose, all the services involved and what kind of data was supposed to be stored and where. Providing the according teams with this set of documents at the start of the project allowed me to start coding and rethinking the project architecture with a clear requirements checklist on the security side. That is how I could smoothly adapt my vision to the constraints we could face such as:
-Keeping all connections on our internal network only
-Encrypting all connections with SSL
-Encrypting the databases with data-at-rest encryption
-Limiting accesses to the databases to the VM used to run the system only using ACLs
-Setting up a firewall to only allow Scaleway VPN connections
-Setting up a OAuth2 authentication method to only allow users from Scaleway to use the service…
Adapting my code and deployment methods to abide by the list above at the deployment stage of the project would likely result in late delivery and lots of breaking changes. So, as a final tip, let me advise you to anticipate, cooperate and adapt before being forced to do it!