
Big, Efficient, Open: The AI Future We Saw Coming
Last week's AI Action Summit highlighted key principles shaping the future of AI: Big, Efficient, and Open. Read the full article for an inside look at the event and insights about it.

Artificial Intelligence (AI) has never moved faster — or been harder to measure.
Every week brings a new model claiming to reason, code, or plan better than the last. Demand for both training and inference hardware keeps growing. Now several years into the great AI boom, Google Scholar and arXiv’s AI and Machine Learning-focused directories continue to receive hundreds of new submissions on a daily basis.
Yet the faster the landscape expands, the more questions the industry faces — proof that an abundance of choice isn’t always a good thing. How do the latest LLMs stack up? Who has the best video generation model? Which model is the fastest with a 100k-token prompt? Last but not least: how much will it cost you?
These questions are why benchmarking matters. From the earliest ImageNet competitions to today’s complex language and reasoning tasks, benchmarks have been the invisible engine of AI advancement. They make progress legible, drive accountability, and help researchers, businesses, and policymakers alike speak a common language.
As models have grown from narrow classifiers to multimodal, reasoning, and even agentic systems, benchmarks have had to evolve in lockstep to more closely reflect the industry’s ever-changing focus.
This piece explores AI benchmarking’s state of affairs: why it matters, who conducts it, and the challenges and opportunities at play.
Benchmarking is the practice of evaluating an AI system’s performance against standardized tests.
A benchmark might be as simple as a dataset of labeled images or as complex as an interactive software environment. What makes it a benchmark are its consistency — every model faces the same challenge, under the same conditions, and produces results that can be compared across time and architectures — and its transparency.
In machine learning’s early days, benchmarks were narrow and task-specific — think image (e.g., ImageNet) or speech recognition (e.g., TIMIT), argument extraction (e.g., TreeBank), and so on. These benchmarks defined the early vocabulary of progress in terms of accuracy, word error rate, and cumulative rewards.
In contrast, modern benchmarks are multidimensional: they assess reasoning, safety, latency, cost, and even energy efficiency. And as the industry comes up with new questions, it continues to require new, more sophisticated benchmarks to answer them.
Benchmarks are more than technical scoreboards. Every breakthrough in AI, from the first convolutional networks to today’s frontier models, has relied on them to quantify improvement, validate new ideas, and facilitate reproduction. Without shared measurement, innovation would remain siloed and anecdotal and everyone would be left guessing whether a new architecture is genuinely more capable than its predecessors, rather than simply different. By making results public and comparable, benchmarks instead enable positive feedback loops to form.
At the end of the day, benchmarking is a tool. As such, it can be used at different stages, from research, to production, to industry-wide governance. Let’s cover each in turn.
Benchmarks enable researchers in a number of ways:
Together, these traits mean innovation happens faster, for less, and spreads more widely.
Benchmarks also underpin the practical side of AI: performance, efficiency, and cost. When you’re processing millions of requests and billions of tokens, every percentage point across any one of those metrics matters. Benchmarking allows companies big and small to access standardized measurements when deciding which hardware, model, or API endpoint to deploy.
As the space gets more crowded, providers have put applicability front and center. Artificial Analysis, for instance, emphasizes that its “benchmark results are not intended to represent the maximum possible performance on any particular hardware platform, they are intended to represent the real-world performance customers experience across providers.”
Benchmarking is also central to the product development process, helping developers and product teams validate their own workflows and assess their products’ performance before general availability or regulatory review. This makes internal benchmarks an indispensable complement to the external-facing tool that are user tests.
Finally, benchmarks are becoming the foundation for AI governance. In recent years, the rapid increase in the technology’s capabilities has raised concerns over the potential risks of its implementation. Newly formed regulatory bodies are now tasked with everything from risk categorization, to defining security, transparency, and quality obligations, to conducting conformity assessments. The tracker maintained by the International Association of Privacy Professionals (IAPP) — last updated in May 2025 — shows extensive global activity, with over 75 jurisdictions having introduced AI-related laws or policies to date.
With that in mind, regulators are increasingly using benchmarks to understand what a model can do before it’s deployed. In particular, they are interested in identifying its behavioral propensities, including a model’s tendency to hallucinate or the reliability of its performance. The UK’s AI Security Institute (AISI), for example, runs independent evaluations of advanced models, assessing areas like biosecurity, cybersecurity, and persuasion capabilities. Its work has set a precedent for government-backed model testing, complementing internal lab efforts and introducing a form of “public audit” for AI safety.
The more central benchmarking became, the more stakeholders started getting involved in hope of shaping the industry’s key metrics and practices. Today, a wide range of actors provides the industry with the information it needs, including:
Together, these initiatives form an invaluable but increasingly complex — and sometimes contradictory — ecosystem.
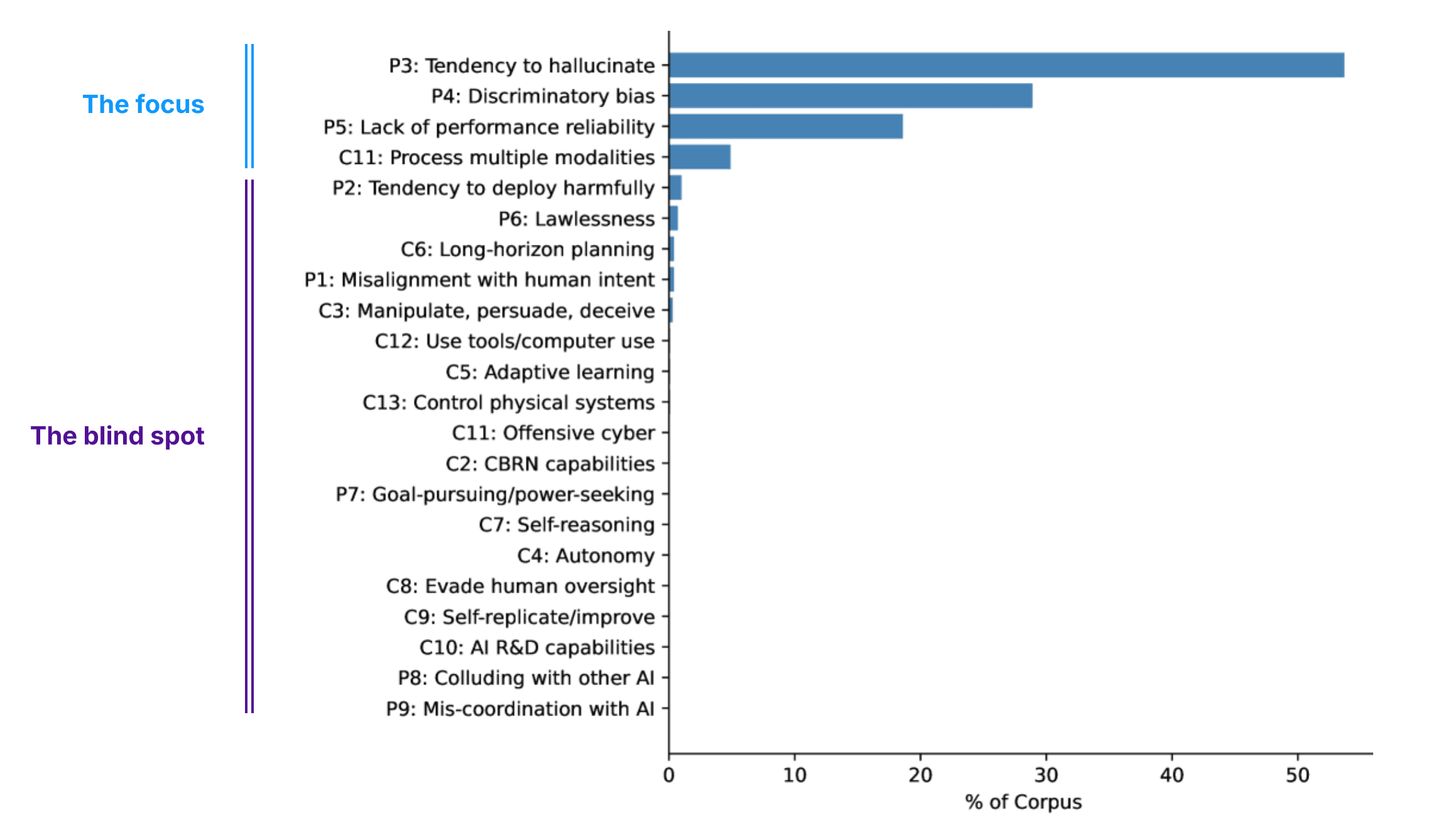
Even as benchmarking becomes more sophisticated, it faces growing pains — Airstreet Capital’s State of AI Report 2025 highlighted that the field’s rapid expansion has outpaced the robustness of its measurements. In no particular order, below are some of its current challenges.
While the above challenges need to be addressed, we should remain optimistic: positive trends are developing that should make benchmarking more useful and reliable, not less. Here are a few of them:
We look forward to seeing how these developments impact the industry for the better!
From its early, task-specific beginnings, benchmarking has evolved into vital infrastructure for the entire field of AI. Today, the combined efforts of the public and private sectors provide the industry with continuously updated data and insights. Benchmarks enable comparison, encourage iteration, and drive discovery, ensuring that competition ultimately benefits everyone.
As the field matures, what we measure may increasingly determine what we build. With concerns over AI safety rising, regulators are relying on benchmarking more and more for practical decision-making, while companies are turning to it for transparency and trust.
At Scaleway, benchmarking is equally central to how we operate. For example, it helps guide the roadmap for our Generative APIs, ensuring we integrate only battle-tested models with proven real-world applicability.
But this relationship also flows the other way: we actively contribute to the benchmarking ecosystem. Our API inference endpoint will soon be featured on Artificial Analysis, giving researchers and businesses direct visibility into our own performance. It’s a small but meaningful step toward greater transparency — a reflection of our continued focus on transparency.
Last week's AI Action Summit highlighted key principles shaping the future of AI: Big, Efficient, and Open. Read the full article for an inside look at the event and insights about it.