IPFS — the ‘real’ web3, explained

The idea of a decentralized internet is nothing new. Napster pioneered peer-to-peer sharing with music in 1999; later on, the term “web3” cropped up in 2014. Four years later, the notion reappeared, this time in a fictional context: HBO’s biting tech satire, Silicon Valley. In one episode, Richard Hendricks imagines an incredible concept for Pied Piper, his startup: quite literally “a new internet. Millions of phones, with that (huge) computing power, are just sitting in people’s pockets. What if we used all of those phones to build a massive network? We would build a completely decentralized version of our current internet. Information would be totally free. I don’t know if it’s possible, but…”
Like so many things in the obsessively well-researched HBO series, the idea was not only totally possible; it already existed. An alternative version of Wikipedia had already been made available built on a decentralized internet. More on that later.
However, since then, the grand idea of a decentralized internet has been bogged down by the hype around web3, which once grew so all-encompassing that it included crypto (which would be used to access ‘premium’ parts of the ‘new’ internet) and the metaverse (e.g. in overhyped experiments like Decentraland). Now that buzz has died down, the true web3 — i.e. ‘pure’ decentralized internet — can emerge. It’s called IPFS.
The basics of IPFS
IPFS stands for InterPlanetary File System (yes, it’s geeky; we’re just getting started!). It can be described as a modular suite of open protocols for organizing and transferring data, which is designed from the ground up with content addressing and peer-to-peer networking.
What’s the core difference between IPFS and HTTP (the internet protocol we all know and love)? Whereas the latter points to a place where we can find a certain piece of content, with IPFS, the content is the destination. IPFS uses Content Identifiers (CIDs), which are used to identify files stored on the IPFS network. Unlike with URLs, the location of those files is irrelevant when retrieving them.
For this sharing to happen, a piece of content — such as a photo of a puppy — needs to be broken into chunks, which are then put into blocks. Every block in IPFS is identified with a CID. Blocks are in turn concatenated into root blocks. If that doesn’t make sense, take a good look at this:

…and if you only retain one thing about IPFS, focus on the right-hand side. Because the way content is put back together via a root block is the real magic of IPFS, as its CID is what you’d essentially give to the person you want to show the picture of your puppy. It’s this that allows the network to be truly decentralized, because the content you want to see has to be recomposed by a series of peers, not by one single destination.
That’s all well and good. But how does it function in a network? If you consider blocks as the (ahem) building blocks of IPFS, what counts is how they are linked to each other, in a decentralized network of nodes, which is open and participative. This is what Richard in Silicon Valley means by “free”: the network isn’t controlled by one or a few dominant actors, but by each and every user.
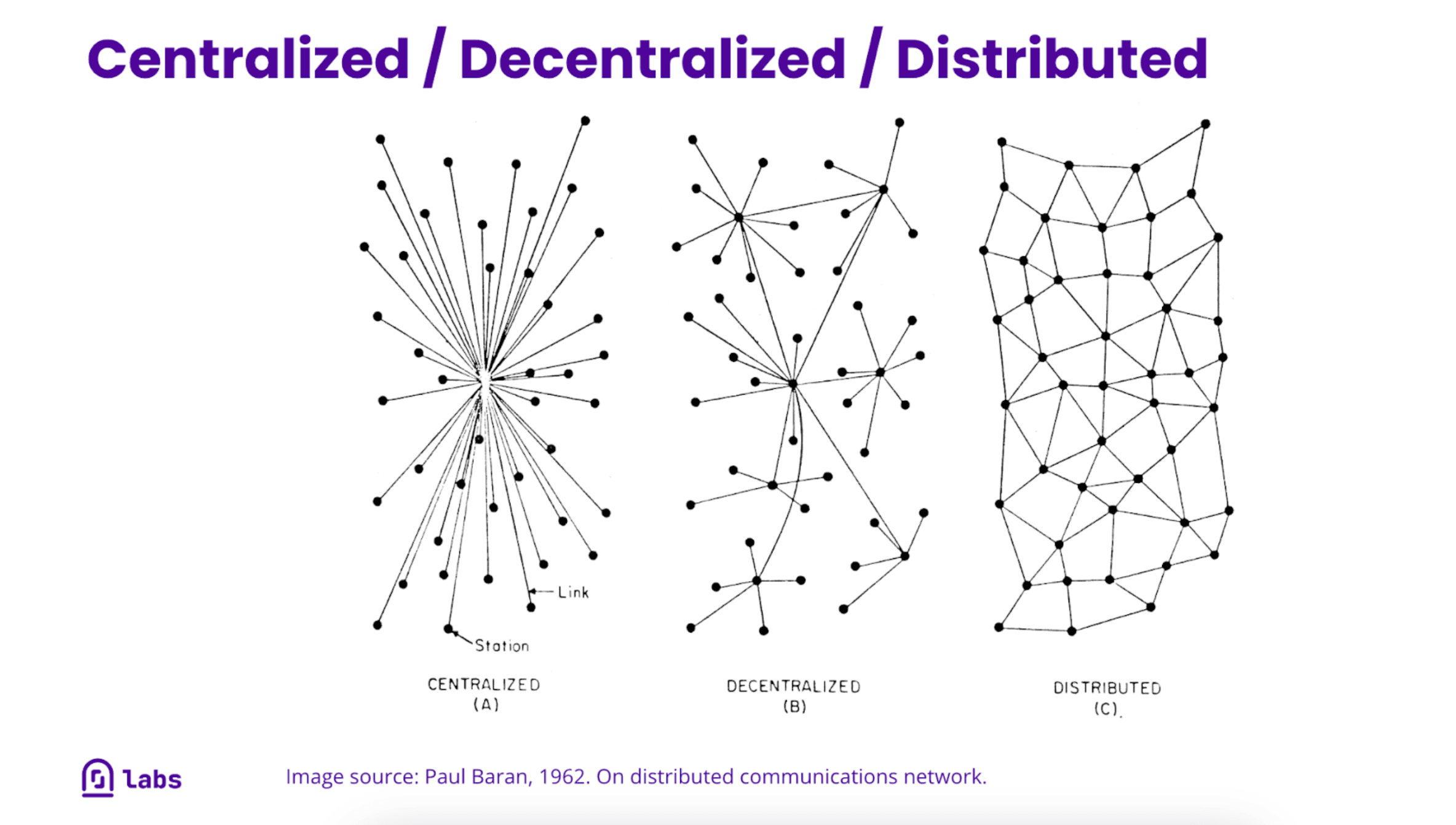
How does the net…work?
All clear so far. But does this distributed net… work? I.e. if this new internet is hosted in everyone’s pockets, how can we make sure data gets from one place to the other, and that that place is the right place?
Nodes, or peers, of an IPFS network are identified by a unique PeerID. This enables two things to happen:
- Content routing, or how IPFS determines where to find a given CID on the network (think Yellow Pages)
- Content exchanging (think… transmission).
Whilst the latter happens primarily through Bitswap, a message-based peer-to-peer network protocol to exchange blocks, content routing occurs in one of four ways:
- Distributed Hash Table
- mDNS (multicast DNS)
- Bitswap (want lists)
- Delegated routing over HTTP.
Step 1 here is crucial, as a Distributed Hash Table, or DHT, is the core way to find content on an IPFS network. DHTs are maintained by Kademlia, the algorithm at the heart of IPFS. Each node maintains a routing table, confirming DHTs’ role as IPFS’ Yellow Pages.
But here’s the catch: CIDs are immutable. Which means that every time you change the content inside it — even a comma — a new CID is created. So how do I find my content, in that case? Get ready for a new acronym: IPNS.
Short for InterPlanetary Naming System, the same IPNS can be used to point to a different CID, for example after the original one has been modified. It uses public key cryptography, like in https or in cryptocurrency wallets, to secure the association.
What’s IPFS for?
So you know how IPFS works now, but the big question remains: why do we need it? As it happens, use cases can actually be traced back to 2017…
- Freedom of speech: six years ago, Wikipedia was banned in Turkey, whose authorities accused it of hosting anti-islamic content. An alternative, uncensorable page was quickly set up on IPFS, and remains visible to this day. Similarly, resources like Anna’s Archive allow previously-censored academic papers to remain online, on IPFS, after sites such as Z-library or Libgen were shut down
- Storage & Hosting: storing content in such a distributed and peer-to-peer way means that if I turn my computer off, you can’t access my content. Ergo, there’s value in storing it in a reliable way. In IPFS, this is called “pinning” content. Always-online services may store content for you, for a fee (naturally; but otherwise, IPFS is volunteer-based, with no incentives, much like open source software). Fleek is, for its part, the place to go to host your website or service on IPFS
- Crypto & NFTs: yes, they’re still on the ‘real’ web3! Filecoin gives users crypto for hosting — or pinning — content; and NFT fans love IPFS, precisely because it makes content immutable and verifiable. Let’s add here for the record that IPFS can’t as such be used for cryptocurrency mining, so it can’t hog energy à la Bitcoin…
- Databases: Orbit db, for example, is a serverless, distributed, peer-to-peer database which automatically syncs with peers… with all the advantages of IPFS
- Video streaming: streaming essentially works by transferring small chunks of data, so it fits well with IPFS, as platforms like ipfs.video demonstrate. Indeed, some claim that IPFS enables bandwidth savings of up to 60% for content like videos, because peer-to-peer networks retrieve pieces of files from multiple nodes at once, whereas HTTP downloads files from one server at a time.
What’s in it for a cloud provider? And for me, for that matter?
As decentralized as it may be, most IPFS data today is pinned (stored) with the world’s biggest cloud providers. Should a smaller, European cloud provider step into this domain, it could offer a decentralized alternative to traditional object storage, whilst ensuring GDPR compliance, as well as baked-in compatibility with the multi-cloud.
As for users, as is often the case, the best way to determine how useful something new is for you is to give it a try. IPFS Gateways like IPFS Companion allow you to access an IPFS network from HTTP. Or you can also try to access IPFS networks directly from your browser, depending on which one it is (hint: Brave is best 🤓)

That said, happy hunting on the ‘other’ internet; you may just meet other Pied Pipers there!
All slide images © Scaleway Labs... who may just have some exciting IPFS news for us soon! Watch this space...