
Introducing GPU Instances: Using Deep Learning to Obtain Frontal Rendering of Facial Images
In this article, we will present a concrete use case for GPU Instances using deep learning to obtain a frontal rendering of facial images.

Nowadays, Graphic Processing Units (GPUs) are presented as the chips making Artificial Intelligence a reality. But, for long, those chips interested mostly gamers and game developers, as they were originally built to efficiently render the stunning graphics one would expect from modern video games.
The connection between these two worlds may not be straightforward. Yet there are, in fact, many similarities in the kind of computations involved in 3D graphics rendering and in chatting with a Large Language Model (LLM). As a result, the surge in demand for AI capabilities caused high-end GPUs to move from gaming rigs to datacenters.
GPUs are great but require a specific development environment to be programmed. Nowadays, CUDA is a very popular GPU programming environment for non-graphical applications. CUDA is a rich ecosystem, widely adopted thanks to its ergonomics, extensive tooling and libraries, and large community of developers. However, it remains fundamentally tied to NVIDIA hardware. This is rather unfortunate since there are many other GPU vendors — the most notable one being AMD — also offering interesting hardware solutions. So, you may wonder: is it possible to run CUDA code on all GPUs?
In this post, we brush off a landscape of the General Purpose GPU (GPGPU) world, starting from the early days of CUDA to the alternative options available today.
In 1999, NVIDIA released what they present as the first GPU: the GeForce 256. It was the first chip capable of handling the whole graphic pipeline — the steps required to turn a scene into a displayable image.
In the past, the transform — i.e., handling object movements or coordinate system changes — and lighting stages of the pipeline used to be performed by the CPU (Central Processing Unit). This was resource- and time-intensive and required a lot of cleverness from game developers — in that regard, Doom was an exceptional piece of code. NVIDIA lifted this limitation by introducing transform and lighting (T&L) units that could handle these operations directly in the hardware.
The GeForce 256 was not only capable of relieving the CPU from T&L operations, it also performed them faster — 2x to 4x faster at that time. But this does not mean that GPUs are fundamentally better than CPUs, only that they are better at this kind of task.
That’s because the two rely on different processes for computation. On the one hand, CPUs use pipelining, whereby different hardware modules operate simultaneously on different data: at the time an instruction is fetched, a second one is decoded, a third one executed, and so on. While the total amount of parallelism achievable remains limited, this approach is suitable to handle complex sequences of operations. GPUs, on the other hand, use something called data parallelism, which enables them to perform the exact same operations on many data points at a time — for example, computing the color of all pixels on your screen at once.
When it became clear that leveraging massive data parallelism was useful beyond the field of computer graphics, developers started using GPUs for general purpose programming. In the beginning, however, GPGPU programming was cumbersome. In the second edition of GPU GEMS (2005), NVIDIA documented how to use vertex and fragment processors — hardware units specialized in texture rendering — to perform more general-purpose computation, for example, to implement sorting algorithms.
Early GPGPU programming was certainly not for the faint of the heart. Fortunately, it has become much easier, thanks to a handful of programming environments that emerged over the years. Let’s cover them in turn.
In 2007, NVIDIA released CUDA: a fully integrated GPGPU programming environment that took advantage of the improved programmability of NVIDIA’s GeForce 8 architecture. Largely inspired by BrookGPU — an early attempt at GPGPU programming from Stanford —, CUDA quickly rose to prominence because it was freely available, was easy to use, and ran on every NVIDIA GPUs, from entry-level graphics card to cutting-edge datacenter solutions.
At its core, CUDA allows you to easily program GPUs with a small superset of C++. The C++ extension allows writing heterogeneous programs (i.e., using both the CPU and the GPU) in the same source code, while keeping the GPU’s management relatively effortless.
In addition, CUDA’s framework is very comprehensive. Today, it includes:
Since acquiring ATI Technologies in 2006, Advanced Micro Devices (AMD) has been NVIDIA’s main competitor on the GPU market. Ten years after the first CUDA release, AMD debuted ROCm (Radeon Open Compute), its own software stack for GPUs. Unlike CUDA, however, most of ROCm is open-source.
The ROCm environment shares many similarities with CUDA. The reason for this is that CUDA became so popular over the years that it ended up setting the market’s expectations for what a productive GPGPU environment should offer. As a result, HIP (Heterogeneous-computing Interface for Portability) — ROCm’s programming model — was designed to be highly interoperable with CUDA, as depicted below.
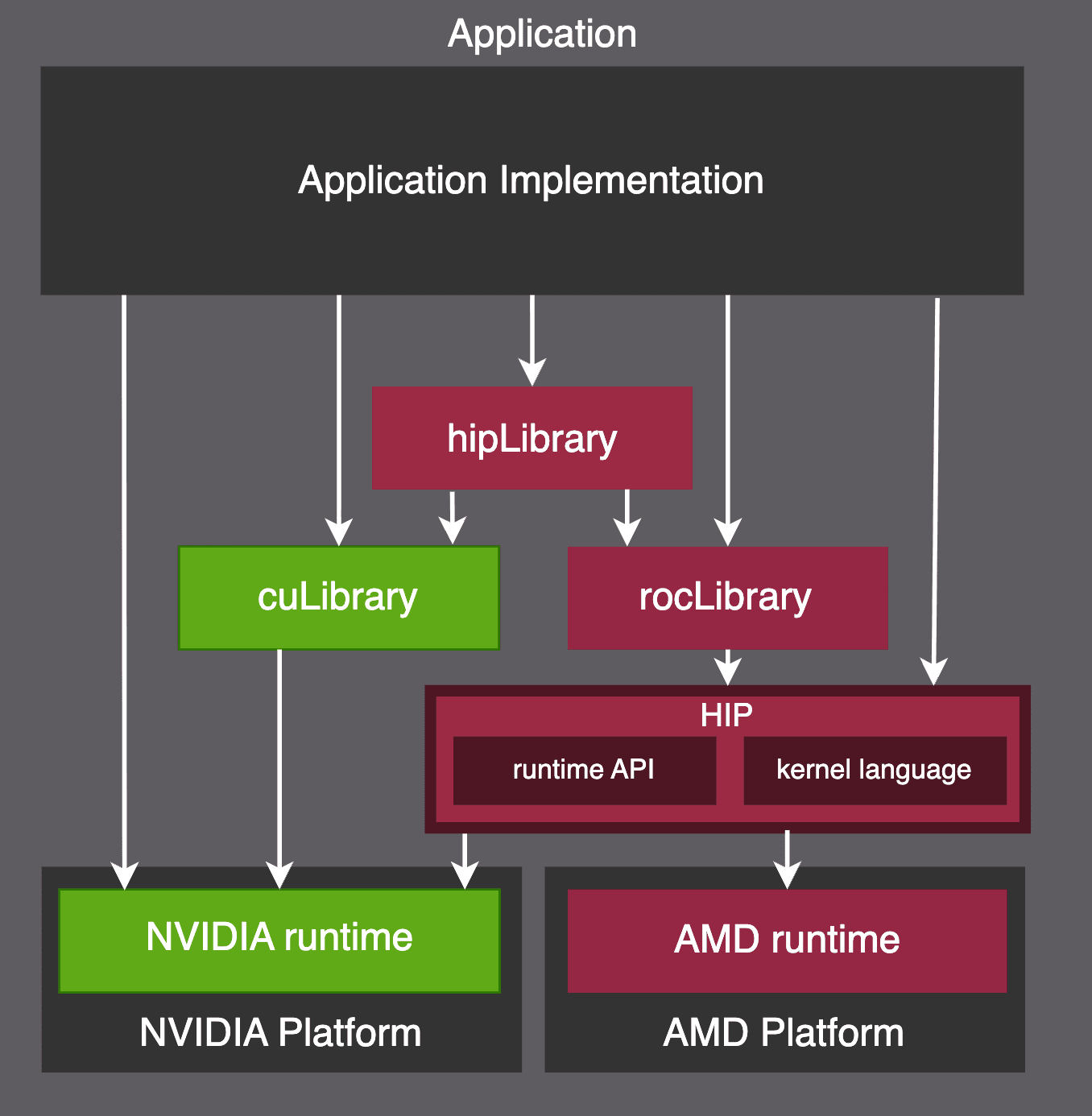
HIP is functionally equivalent to CUDA, and AMD provides tools to easily port CUDA code base to the ROCm environment. For example, one of the key porting tools is HIPIFY, which can transpile CUDA code into its HIP counterpart. The port can be really straightforward. For example, the cudaGetDevice() function call can be replaced by hipGetDevice() using a simple text substitution. Meanwhile, PyTorch’s ROCm backend is generated automatically from CUDA code using HIPIFY.
AMD’s HIPIFY tools can convert most CUDA code into HIP, but this interoperability has limits. Architecture-specific features like inline PTX — NVIDIA’s virtual assembly language — still require manual porting to other targets.
To overcome this limitation, in July 2024, a team at Spectral Compute unveiled the first public beta of SCALE, a new compiler that aims to translate 100% of CUDA code into HIP-compatible code. As of today – version 1.4.2, released in October 2025 – only AMD GPUs are currently supported, but the goal is to ultimately support any hardware accelerator.
SCALE works with a kind of virtual environment called scalenv that shadows nvcc so the compilation process is transparent to the user. However, the toolchain currently does not support enough CUDA APIs to port significant frameworks like PyTorch. A list of supported third-party software can be found on a dedicated GitHub repository.
Both AMD’s HIPIFY and Spectral Compute’s SCALE require recompiling the CUDA code. ZLUDA, on the contrary, works on the binary produced by nvcc. This solution has two benefits: first, it does not require the source code, and thus no effort to compile it; second, it takes advantage of the optimisations provided by nvcc.
ZLUDA started at Intel in 2020 before moving to AMD two years later, and is now handled by two independent developers. For these reasons, the latest release (version 5, October 2025) is still far from covering all cases, but claims the ability to run llama.cpp — as a comparison, version 4 was experimental and only supported Geekbench 5. The project could also face licensing issues. Indeed, the CUDA license appears to forbid any attempt at translating the output generated by the CUDA SDK to target a non-NVIDIA platform.
In recent years, China has turned into a major actor in the development of AI, with its own blooming technological ecosystem. Names like Moore Threads, Hygon, Ascend, KunlunXin, Enflame or Cambricon may not ring a bell, but they are some of the dozens of new GPU vendors — sometimes backed by China’s tech giants — now offering chips for the Chinese domestic market.
Most of these companies are still small, but they are likely to grow quickly, particularly since the Chinese government in September 2025 banned NVIDIA chips for AI applications in favor of local vendors. All these vendors have their own software stacks and, as with AMD’s, these stacks are greatly inspired by CUDA. Some of them — like Huawei with its flagship 910C — even claim to natively support CUDA.
While these options may not yet be popular outside China, they are likely to gain traction in the future.
CUDA is clearly the most common platform for GPU acceleration, but it is specific to NVIDIA. However, there exist ways to convert this code so it can be run on AMD GPUs. These tools are at different maturity levels for now, but they are all aiming for full compatibility further down the line. Meanwhile, new xPU vendors, notably in China, consider CUDA hegemony as a given and are making their tools directly targeting this language. In short, the available range of “CUDA-compatible” hardware seems poised to grow — a boon for all developers.
In this article, we will present a concrete use case for GPU Instances using deep learning to obtain a frontal rendering of facial images.

What do you need to know before getting started with state-of-the-art AI hardware like NVIDIA's H100 PCIe 5, or even Scaleway's Jeroboam or Nabuchodonosor supercomputers? Look no further...