
AI in practice: Generating video subtitles
In this practical example, we roll up our sleeves and put Scaleway's H100 Instances to use by leveraging a couple of open source ML models to optimize our internal communication workflows.

Open source makes LLMs (large language models) available to everyone. There are plenty of options available, especially for inference. You’ve probably heard of Hugging Face’s inference library, but there’s also OpenLLM, vLLM, and many others.
The main challenge, especially if you’re a company like Mistral AI building new LLMs, is that the architecture of your LLM has to be supported by all these solutions. They need to be able to talk to Hugging Face, to NVIDIA, to OpenLLM and so on.
The second challenge is the cost, especially that of the infrastructures you’ll need to scale your LLM deployment. For that, you have different solutions:
Then you have to decide whether you host it yourself; you use a PaaS solution; or ready-to-use API endpoints, like what OpenAI does.
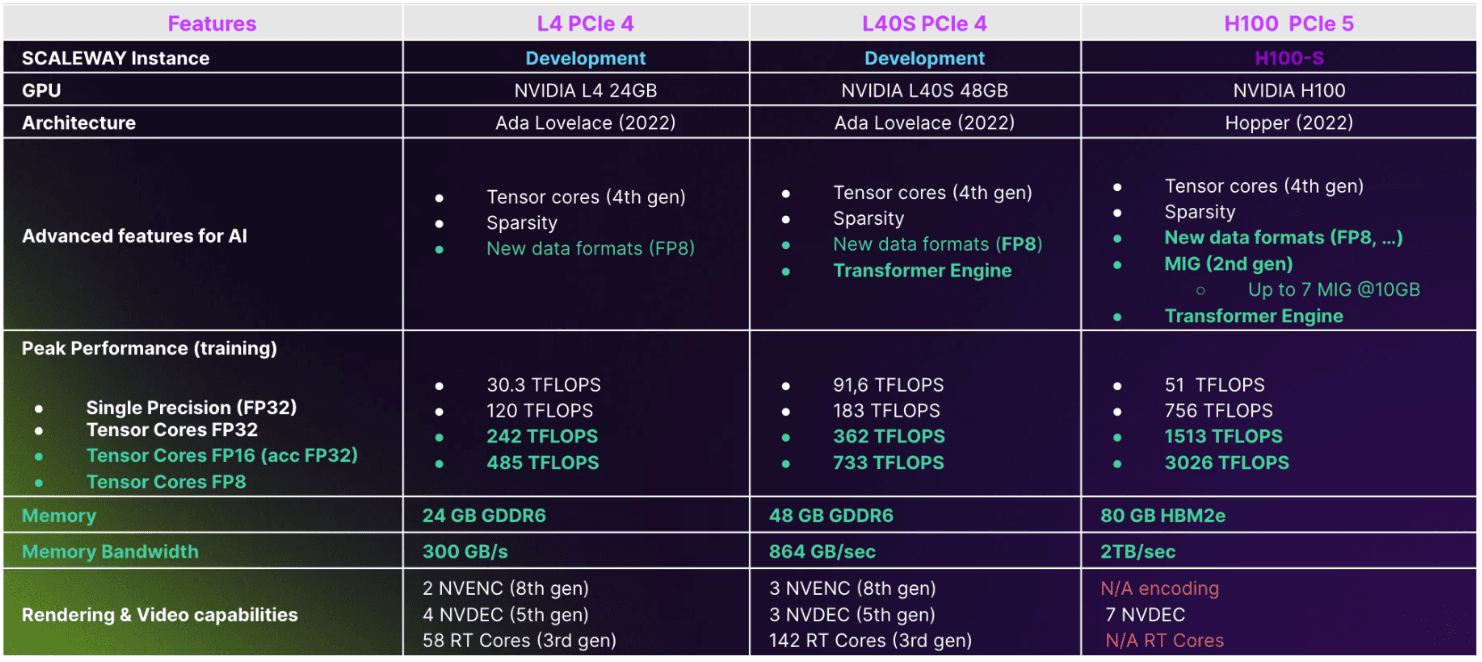
The above is Scaleway’s offering, but similar offerings are currently being installed with most major cloud providers.
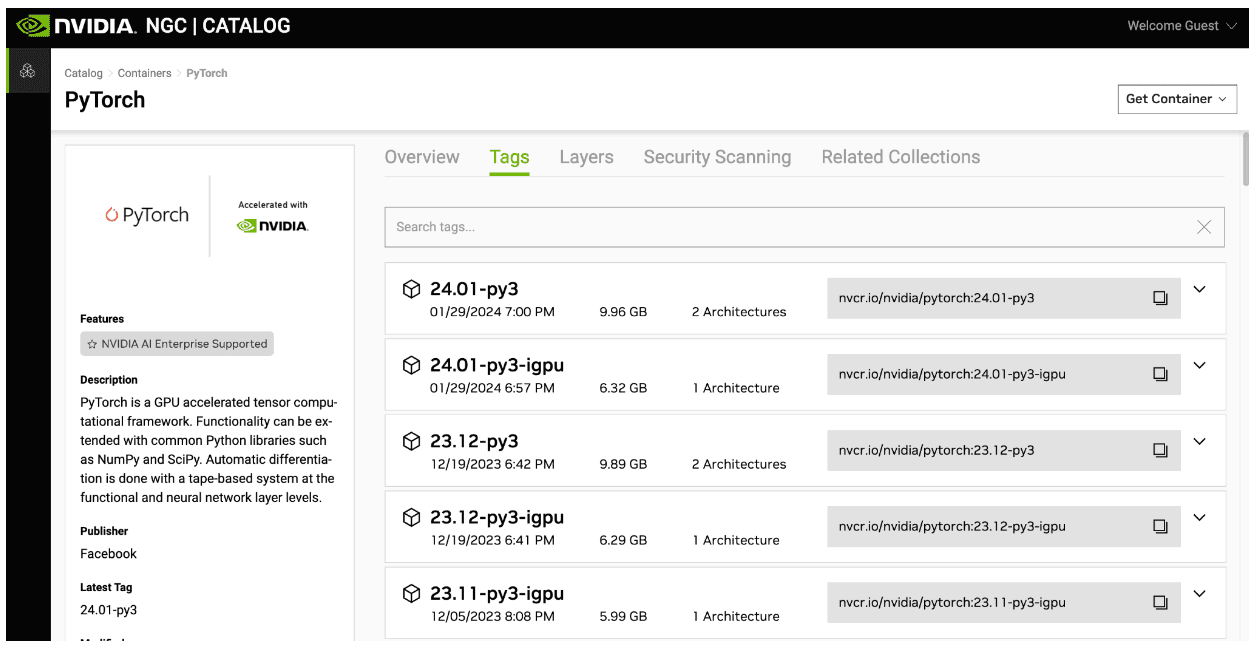
When using GPUs, use Docker images, and start with those offered by NVIDIA, which are free. This way, the code is portable, so it can run on your laptop, on a workstation, on a GPU Instance (whatever the cloud provider, so without lock-in), or on a powerful cluster (either with SLURM as the orchestrator if you’re in the HPC/AI world, or Kubernetes if you’re more in the AI/MLOps world).
NVIDIA updates these images regularly, so you can benefit from performance improvements and bug/security fixes. A100 performance is significantly better now than it was at launch, and the same will apply to H100, L4 and so on. Also, there are a lot of time-saving features, which will allow you to make POCs more quickly, like framework and tools like NeMo, Riva and so on, which are available through the NGC catalog (above).
This also opens up the possibility to use an AI Enterprise license on supported hardware configurations, which is something typically only seen in cloud provider offers), which will give you support in case you meet bugs or performance issues, and even offers help from NVIDIA data scientists, to help you debug your code, and to get the best performance out of all of these softwares. And of course, you can choose your favorite platform, from PyTorch, TensorFlow, Jupyter Lab and so on.
In Scaleway’s GPU OS 12, we’ve already pre-installed Docker, so you can use it right out of the box. I’m often asked why there’s no CUDA or Anaconda preinstalled. The reason is these softwares should be executed inside the containers, because not all users have the same requirements. They may not be using the same versions of CUDA, cuDNN or Pytorch, for example, so it really depends on the user requirements. And it’s easier to use a container built by NVIDIA than installing and maintaining a Python AI environment. Furthermore, doing so makes it easier to reproduce results within your trainings or experiments.
So basically, you do this:
## Connect to a GPU instance like H100-1-80Gssh root@<replace_with_instance_public_ip>## Pull the Nvidia Pytorch docker image (or other image, with the software versions you need)docker pull nvcr.io/nvidia/pytorch:24.01-py3[...]## Launch the Pytorch containerdocker run --rm -it --runtime=nvidia \-p 8888:8888 \-p 6006:6006 \-v /root/my-data/:/workspace \-v /scratch/:/workspace/scratch \nvcr.io/nvidia/pytorch:24.01-py3## You can work with Jupyter Lab, Pytorch etc…It’s much easier than trying to install your environment locally.
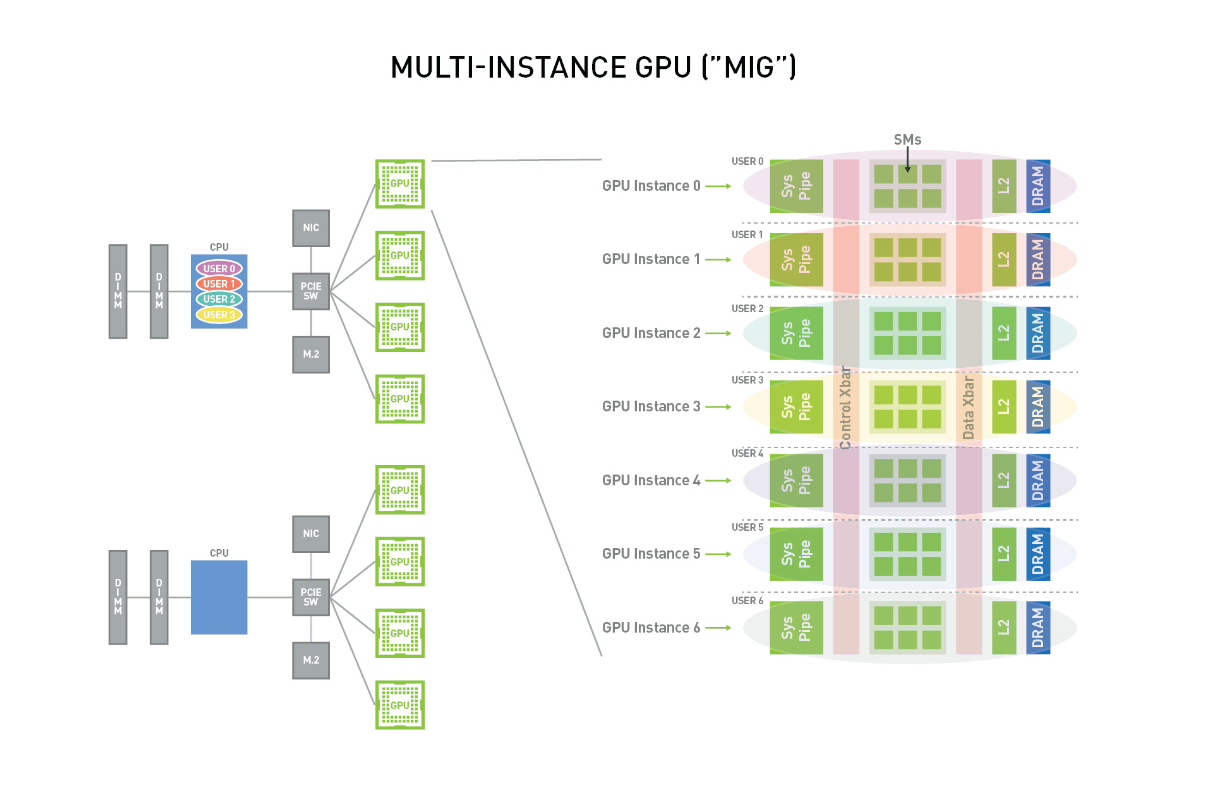
One unique feature of the H100 is MIG, or multi-instance GPU, which allows you to split your GPU into up to seven pieces. This is really useful when you want to optimize your workload. If you have workloads that don’t fully saturate GPUs, this is a nice way to have multiple workloads and maximize GPU utilization. It works with standalone VMs, and works really easily in Kubernetes. You request one GPU reference corresponding to the split you want to use for one GPU resource.
In Kubernetes, it’s is as easy as replacing in your deployment file the classic resource limits
nvidia.com/gpu: '1'. by the desired MIG partition name, for example, nvidia.com/mig-3g.40gb: 1
Here’s the link if you want to look into that.
All the latest generation of GPUs (available in the latest Nvidia GPU architecture, namely Hopper and Ada Lovelace) use the NVIDIA Transformer Engine, a library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper and Ada GPUs, to provide better performance with lower memory utilization in both training and inference.
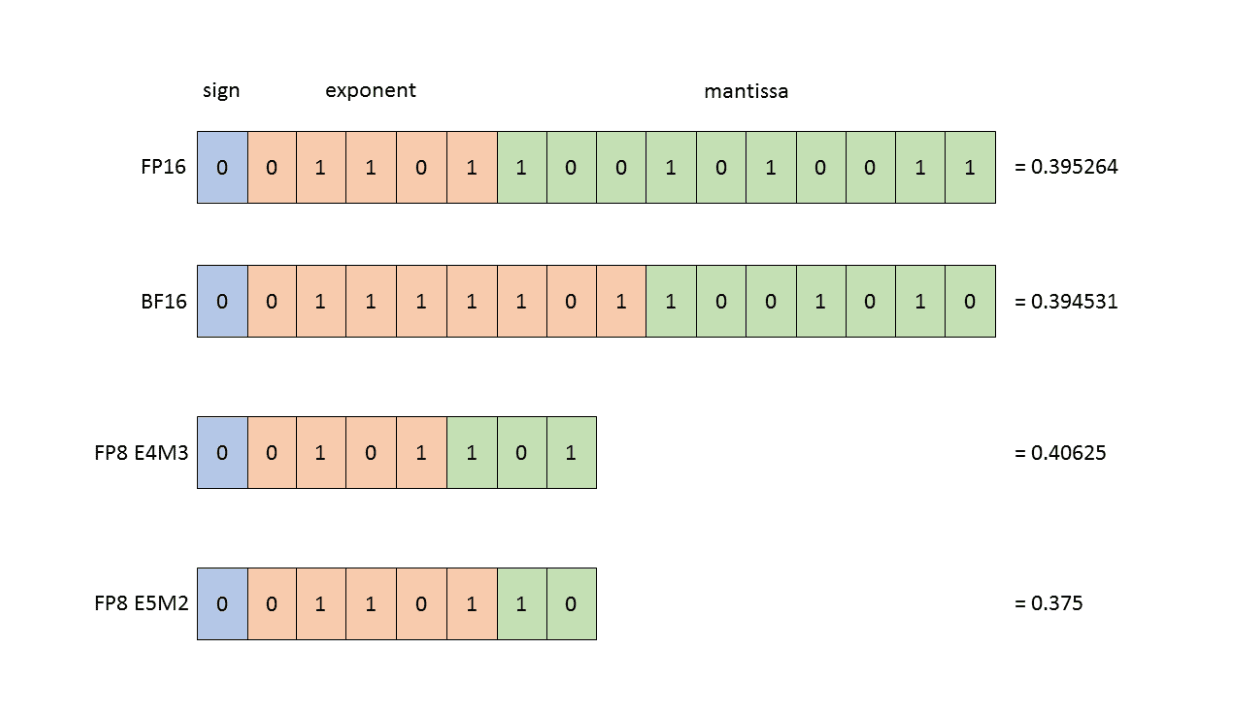
As for their use of the FP8 data format, there are actually two kinds of FP8, which offer a tradeoff between the precision and the dynamic range of the numbers you can manipulate (cf. diagram). When training neural networks, both of these types may be utilized. Typically forward activations and weights require more precision, so the E4M3 datatype is best used during forward pass. In the backward pass, however, gradients flowing through the network typically are less susceptible to the loss of precision, but require higher dynamic range. Therefore they are best stored using E5M2 data format. This can even be managed automatically with the 'HYBRID' format (more information here).
The Transformer Engine is not just for Transformers. As it can also optimize Linear operations, it can benefit other model architectures, like computer vision (cf. the MNIST example) So basically, you install the Transformer engine package with ‘pip’, load the package, and just test or replace certain operant modules (from your favorite deep learning frameworks) by the one provided in the Transformer engine package (cf. the MNIST example above). If you want to invest a bit of time in optimizing your code by using the Transformer Engine and the FP8 format in your code, you can. It’s good here to optimize, because you’ll use less memory, fit more variables, and speed up your inference and your training. So be sure to optimize your code!
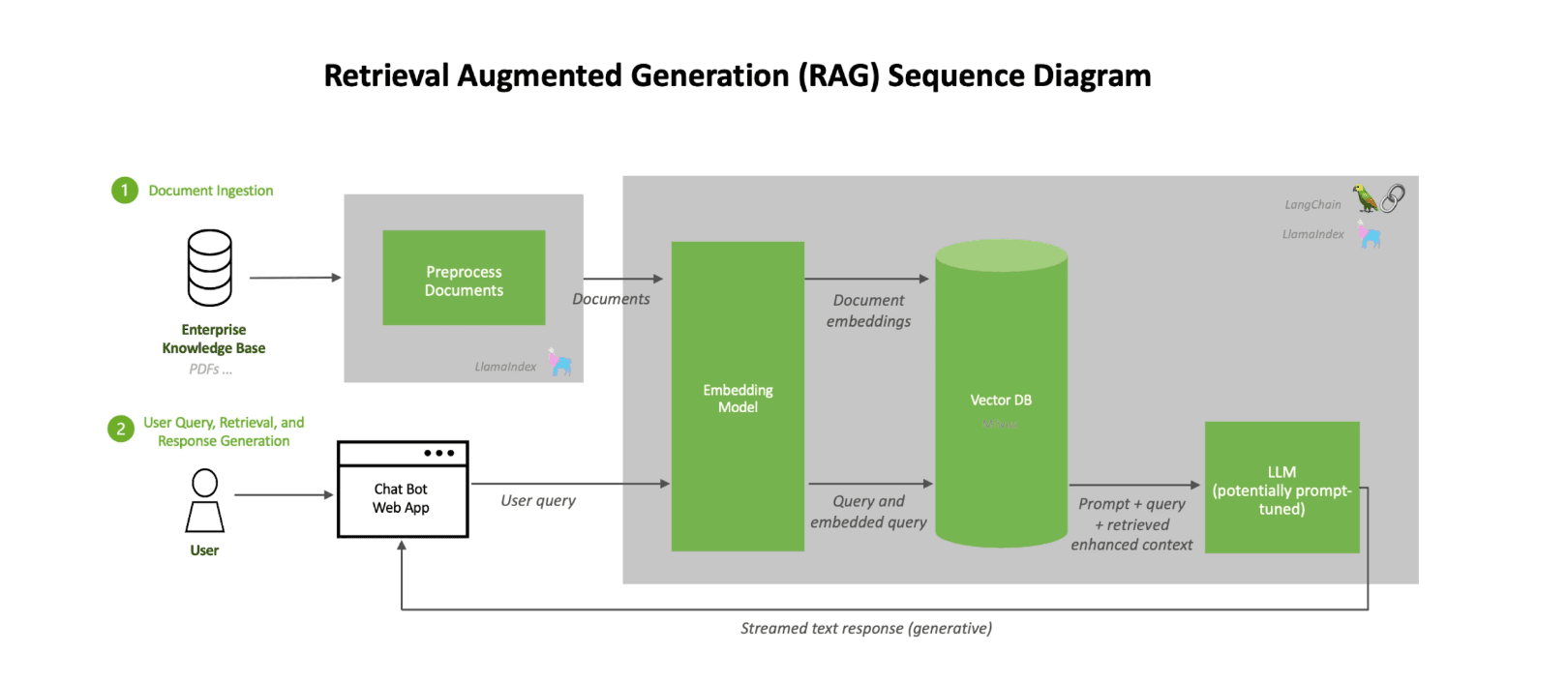
If you want to do LLMs in production, you might want to create a chatbot, and to do that, you’ll probably want to fine-tune a model on your data for your specific use case. It’s easy with Hugging Face’s Transformers library in terms of code; but it can be hard to improve your results, as this takes lots of trial and error.
Another technique is to look at RAG, or Retrieval Augmented Generation, which you can do before fine-tuning, or instead of it. This way there’s less risk of breaking the model, as is a risk with fine-tuning. Plus with RAG, there’s no fine-tuning cost, as you don’t pay for the GPU usage of the multiple tries that fine-tuning requires; and you can keep your data private by hosting it locally. Furthermore, you reduce the risks of hallucinations, which are always a bad thing when you’re trying to build an AI chatbot for your business. So I’ve included the documentation that explains this system. NVIDIA even has a GitHub project to allow you to build your first AI chatbot with RAG in just five minutes.
Firstly, a lot of money! LLaMA’s white paper says it took 21 days to train LLaMa using 2048 A100 80GB GPUs. We can't possibly speculate on what that costs, but someone else has here (hint: it's a lot!)
You’ll also need a team of experts… but not necessarily hundreds! Mistral AI’s Mixture beat GPT3.5 (according to Mistral AI’s benchmark) with a team of less than 20 people.
Lots of data will also be required: you may have to scrape the internet for that, or rely on a partnership to help you. Then the data will need to be prepared, i.e. cleaned and deduplicated.
Finally, you’ll need lots of compute power! If we look at this NVIDIA graphic:
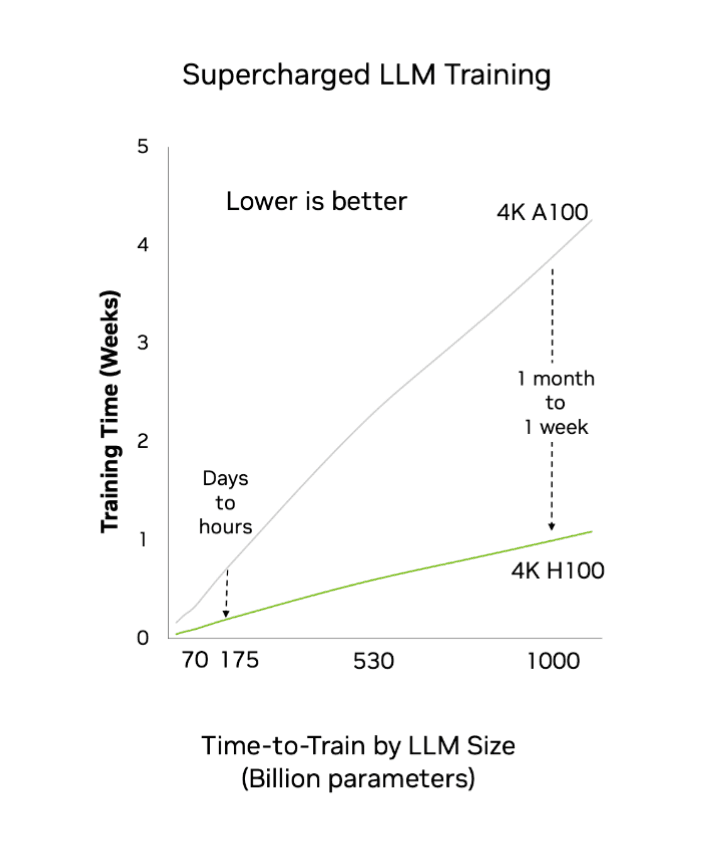
…we see there’s a big leap between A100 and H100 (from one month to one week’s training time for the biggest models).
Our Superpod customers use Spark for the data preparation, which uses CPUs (in the range of 10 000 vCPUs), and around 100 TB of block storage, before the dataset is stored in Object Storage. Scaleway is currently working on a Spark managed cluster offer, by the way: watch this space!
NVIDIA also provides tools like NeMo data Curator (through NGC/Nvidia AI Enterprise, so we’re talking about containers), which has functions like data download and text extraction, text re-formatting and cleaning, quality filtering, document-level deduplication, multilingual downstream-task decontamination and more.
Even with these tools, data preparation can take a long time, but it has to be done before you start the training.
To start training, you’ll need more than one GPU, so the building blocks will be NVIDIA DGX H100, which are ready-to-use computers with a set maximal server configuration, so you’ve got the best of the best:
To build a Superpod, you take that server, then put 32 of them together, no more, no less. That's what NVIDIA calls a Scaleable Unit. If you scale up four scalable units, you have 128 nodes, and that’s the SuperPOD H100 system. Each of the four units is 1 ExaFLOPS of FP8 format for a total of up to 4 ExaFLOPS in FP8, and the cluster is orchestrated by NVIDIA Base Command Manager, so NVIDIA software, with a SLURM orchestrator, which can launch jobs across multiple computers to do the training.
So at Scaleway, we’ve got two supercomputers:
Jeroboam, the smaller version of the cluster, which was intended to learn to write code that’s multi-GPU and multi-nodes:
2 NVIDIA DGX H100 nodes (16 Nvidia H100 GPU)
Up to 63,2 PFLOPS (FP8 Tensor Core)
8 Nvidia H100 80GB SXM GPUs with NVlink up to 900 GB/s per node
Dual CPU Intel Xeon Platinum 8480C (112 cores total at 2GHz)
2TB of RAM
2x 1.92TB NVMe for OS
30,72 TB NVMe for Scratch Storage
Throughput (for 2 DGX) : Up to 40 GB/s Read and 30 GB/s Write
Nvidia Infiniband GPU interconnect network up to 400 Gb/s (at cluster level)
60TB of DDN high-performance, low latency storage.
Nabuchodonosor, the ‘real thing’ for training, which is also built for people who’ll want to train LLMs with videos, not just text, thanks to the large amount of high-performance storage…
127 NVIDIA DGX H100 nodes (1016 Nvidia H100 GPU)
Up to 4 EFLOPS (FP8 Tensor Core)
8 Nvidia H100 80GB SXM GPUs with NVlink up to 900 GB/s per node
Dual CPU Intel Xeon Platinum 8480C (112 cores total at 2GHz)
2TB of RAM
2x 1.92TB NVMe for OS
30,72 TB NVMe for Scratch Storage
Nvidia Infiniband GPU interconnect network up to 400 Gb/s (at cluster level)
1,8PB of DDN high-performance, low latency storage
Throughput (for 127 DGX) : Up to 2,7 TB/s Read and 1,95 TB/s Write
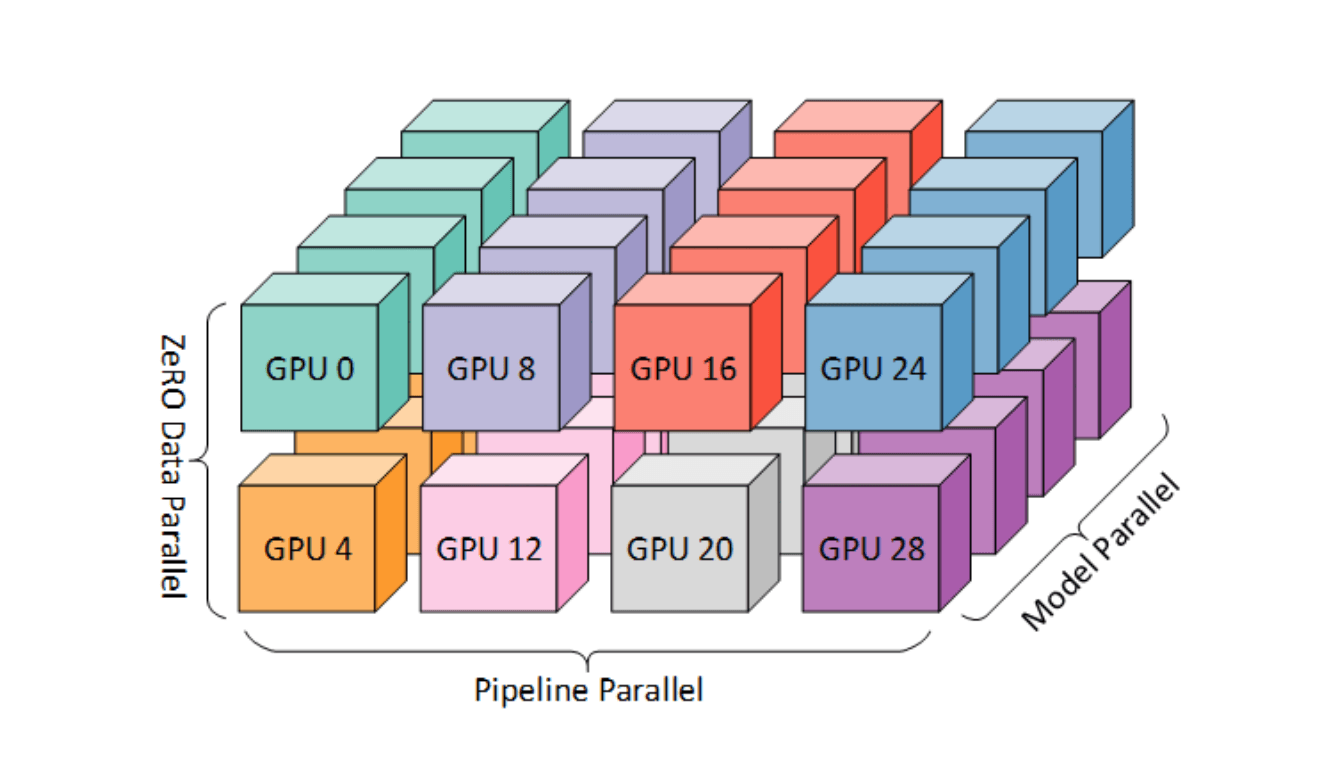
The challenge of training LLMs on Nabuchodonosor is that it’s an HPC user experience, which means SLURM jobs, not Kubernetes. It’s still containers, though, which you build on top of NVIDIA NGC container images (Pytorch, Tensorflow, Jax…). That’s why when you write your code with these NGC images, even with a single small GPU, your code will be able to scale more easily. One best practice is if you have, say, 100 nodes, don’t launch your jobs on all of them. Keep a few spare in case one or two GPUs fail (it happens!) That way, if you have any issues, you can relaunch your jobs by replacing the faulty nodes.
You’ll need to write your code in special ways, to maximize performance by using data parallelism and model parallelism (computing across multiple GPUs at the same time); you can use resources like Deepspeed for this.
Then there’s the End-to-End framework Nvidia NeMo, which will also help you build, finetune and deploy generative AI models.

Scaleway’s supercomputers were built in just three to seven months, so it was quite a logistical challenge to make sure all the parts were received in time, and connected the right way… with more than 5000 cables!
Providing power is also quite a challenge: the Nabuchodonosor Superpod system’s power usage is 1.2 MW, which means we can only put two DGX units in each rack, so it’s not a great usage of data center surface space. Then there’s the cost of electricity, which is five times more in France than in the USA, for example. But as French electricity’s carbon intensity is very low, it generates around seven times less emissions than in Germany, for example. Furthermore, as all of Scaleway’s AI machines are hosted in DC5, which has no air conditioning and therefore uses 30-40% less energy than standard data centers, we can say this is one of the world’s most sustainable AI installations. More on AI and sustainability here.
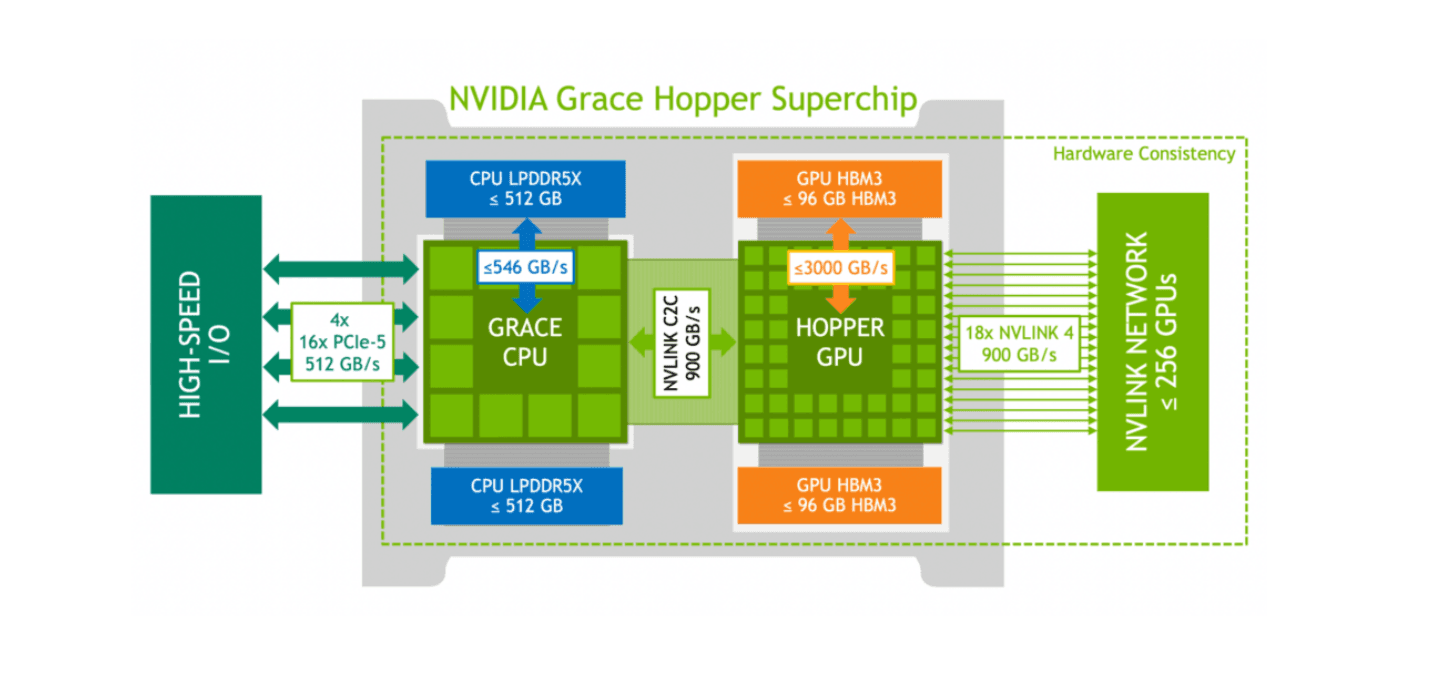
Scaleway will launch this year the NVIDIA GH200 Grace Hopper Superchip, which combines Grace ARM CPUs with Hopper GPUs in the same device, which are linked at 900 GB/s. You can connect 256 of these devices together, which is much larger than what you can connect in the DGX configuration described above (the 8 GPUs connected at 900 GB/s with NVlink in a single DGX H100 server node). And if you need more you can even connect several mesh of 256 GH200 via Infiniband at 400Gb/s. So it’s really for use cases where the memory is the bottleneck, so it’s really for HPC, and for inference of LLMs. When they’re all put together, it’s like a giant GPU, designed for the most demanding use cases, like healthcare and life sciences, for example.
In this practical example, we roll up our sleeves and put Scaleway's H100 Instances to use by leveraging a couple of open source ML models to optimize our internal communication workflows.

How can AI remain innovative whilst complying with regulations and standards? French startup and ai-PULSE exhibitor Giskard.AI has the answer...