- NVIDIA Blackwell (2024)
- 8 GPUs NVIDIA B300-SXM
- 288 GB VRAM (HBM3e, 7.7 TB/s)
- 224 vCPUs (Xeon 6)
- 3,840 GB DDR5 RAM
- 23.3 TB ephemeral Scratch NVMe
- 99.5% SLA
Billed per minute
¹ Price and specs for 8 GPUs
Finding the right GPU instance can be tricky, but we've made it easy. We have a wide range of offerings available, so you can explore all your options and compare them side-by-side.

With thousands of machines, Scaleway has one the largest fleet of GPU Instances in Europe. We give European AI startups the tools to create products that revolutionize how we work and live, without a considerable CAPEX investment.
Billed per minute
¹ Price and specs for 8 GPUs
Ideal for LLM fine-tuning and larger LLM model Inference.
From €6.61/GPU/hour¹
Billed per minute
¹ Price and specs for 2 GPUs
Billed per minute
Billed per minute
Billed per minute
Find your ideal AI solution
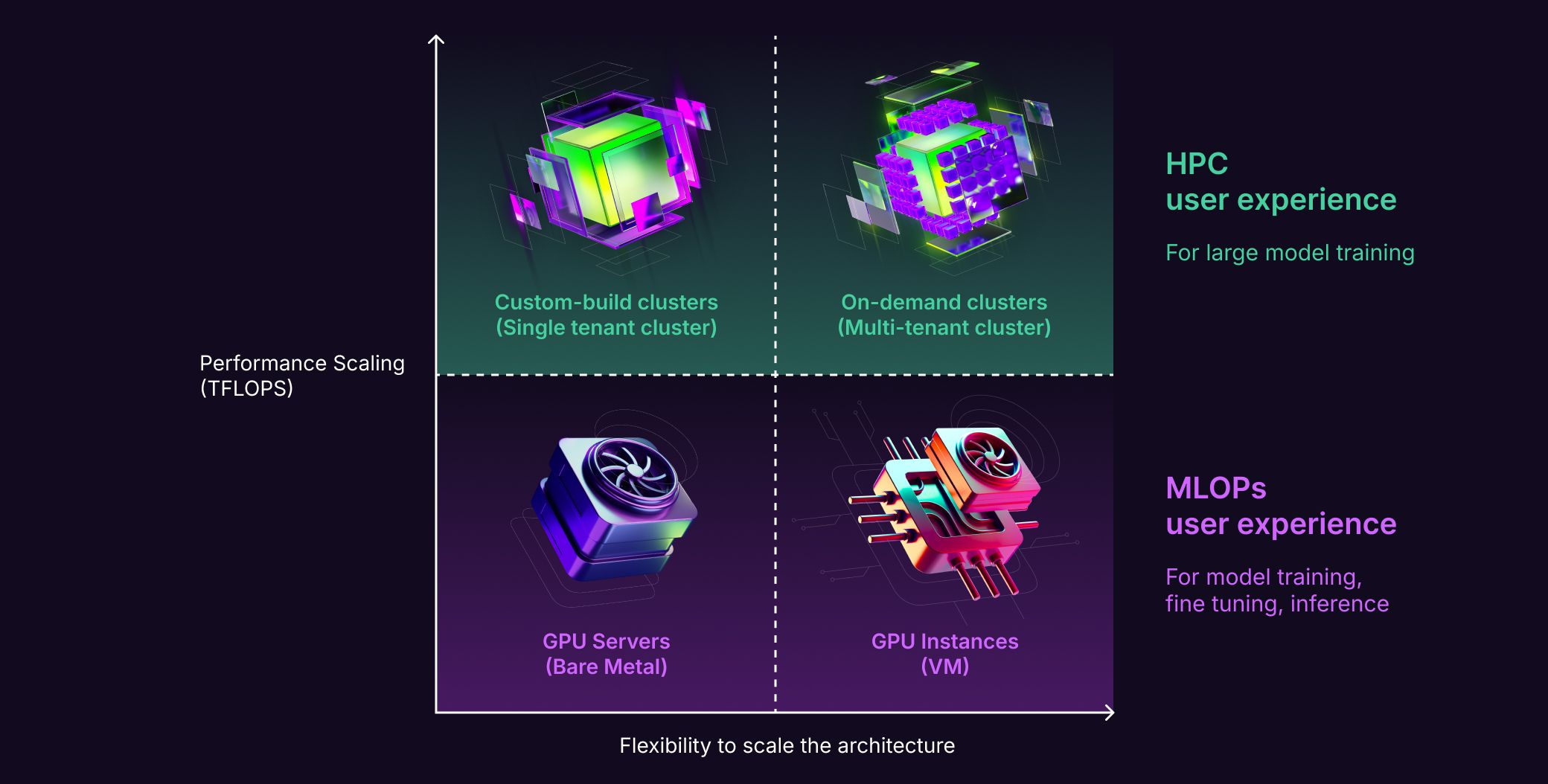
GPU Instances are perfect for workloads such as Inference LLM and AI chatbots, with flexible configurations to suit your needs.
For large-scale AI and high-performance computing (HPC) tasks, our AI Supercomputers deliver exceptional computational power and are optimized for intensive parallel processing.
Whether you need flexibility or specialized, high-performance resources, we provide the right solution for your AI and HPC workloads.
| Option and value | Price |
|---|---|
| ZoneParis 1 | |
| Instance1x | 0€ |
| Volume10GB | 0€ |
| Flexible IPv4No | 0€ |
Graphical Processing Units (GPU) are specialized hardware originally designed for rendering graphics in video games and other 3D applications. However, their massively parallel architecture makes them ideal for various high-performance computing tasks, such as deep learning, massive machine learning, data processing, scientific simulations, and more.
A cloud GPU Instance refers to a virtual computing environment that offers access to powerful GPUs over the internet.
Our GPU Instances are available in the fallowing regions: Paris (PAR-2, and also PAR-1 for the L4 GPU Instance) and Warsaw (WAW-2). You can check the Instance availability guide to discover where each GPU Instance is available.
You can opt for a “pay as you go” model (by the minute), paying only for what you consume. This approach gives you the flexibility to provision resources and delete resources when needed.
GPU OS 12 is a specialized OS image based on Ubuntu 24.04 (Noble), optimized for GPU-accelerated workloads. It comes pre-installed with the NVIDIA driver, Docker, and NVIDIA's Container Toolkit, providing an environment for running containerized applications. This image is designed to work efficiently with NVIDIA NGC container images, enabling rapid deployment of GPU-accelerated applications, such as machine learning and data processing workloads.
Yes, we offer a 99.5% SLA on all GPU Instances. Learn more here.
Scaleway offers 4 different support plans to match your needs: Basic, Advanced, Business, and Enterprise. You can find all the information, including pricing, here.