Introduction to Kubernetes - Understanding K8s concepts
Kubernetes (K8s) is an open-source platform for managing containerized workloads and services. Google initially developed the project, and it was made publicly available in 2014. Since then, it has a vast, rapidly growing ecosystem. The name Kubernetes derives from the ancient Greek word meaning helmsman or pilot.
This page explains the concept and the different compartments of Kubernetes.
From traditional deployment to containerized deployment
To understand why Kubernetes and containerized deployment is so useful for nowadays workloads, let us go back in time and have a view on how deployment has evolved:
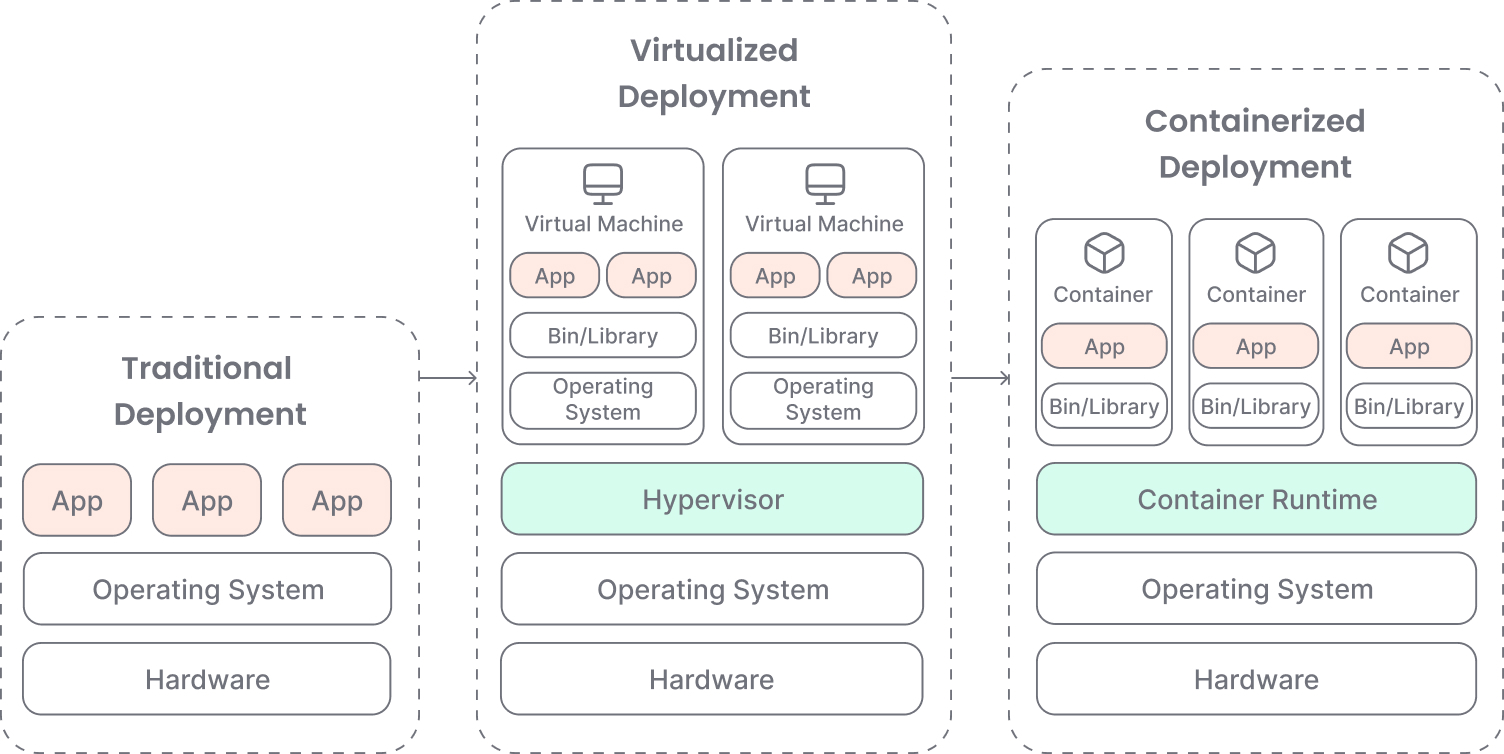
During the traditional deployment era, organizations ran applications directly on physical servers. There was no way to control the resources an application may consume, causing resource allocation issues. If an application consumed most of the resources of the server it ran on, this high load might have caused performance issues on other applications running on the same physical server.
A solution would be to run each application on a dedicated server, but this would cause resources to be under-used and maintenance costs to increase.
Multiple Virtual Machines (VMs) brought a beginning of solution during the virtualized deployment era. Virtualization allowed applications to be isolated between different VMs running on the same physical server, providing a security layer and better resource allocation.
As this solution reduces hardware costs, each VM still requires the same administration and maintenance tasks as a physical machine.
The containerized deployment era brought us the concept of containers. A container includes its running environment and all the required libraries for an application to run. Different containers with different needs can now run on the same VM or physical machine, sharing resources. Once configured, they are portable and can be easily run across different clouds and OS distributions, making software less and less dependent on hardware and reducing maintenance costs.
How Kubernetes can help you to manage containerized deployments
In a production environment, you may need to deal with huge amounts of containers, and you need to manage the containers running the applications to ensure there is no downtime.
Managing thousands of simultaneously running containers on a cluster of machines by hand sounds like an unpleasant task.
This is what Kubernetes can do for you. It manages the lifecycle of containerized applications and services and defines how applications should run and interact with other applications in the outside world while providing predictability, scalability, and high availability.
Kubernetes architecture
Kubernetes is able to manage a cluster of virtual or physical machines using a shared network to communicate between them. All Kubernetes components and workloads are configured on this cluster.
Each machine in a Kubernetes cluster has a given role within the Kubernetes ecosystem. One of these servers acts as the control plane, the "brain" of the cluster exposing the different APIs, performing health checks on other servers, scheduling the workloads and orchestrating communication between different components. The control plane acts as the primary point of contact with the cluster.
The other machines in the cluster are called nodes. These machines are designed to run workloads in containers, meaning each of them requires a container runtime installed on it (for example, Docker or CRI-O).
The different underlying components running in the cluster ensure that the desired state of an application matches the actual state of the cluster. To ensure the desired state of an application, the control plane responds to any changes by performing necessary actions. These actions include creating or destroying containers on the nodes and adjusting network rules to route and forward traffic as directed by the control plane.
A user interacts with the control plane either directly with the API or with additional clients by submitting a declarative plan in JSON or YAML. This plan, containing instructions about what to create and how to manage it, is interpreted by the control plane who decides how to deploy the application.
Kubernetes components
Control plane components
These main components form the cluster's control plane. These components are making global decisions about the cluster, as well as detecting and responding to cluster events.
Multiple applications and processes are needed for a Kubernetes cluster to run. They can be components guaranteeing the cluster's health and status, or processes allowing communication and control over the cluster.
etcd
etcd is a consistent and highly-available key-value store that is used by Kubernetes to store its configuration data, its state, and its metadata.
kube-apiserver
The kube-apiserver is a component on the control plane that exposes the Kubernetes API. It is the front end of the Kubernetes control plane and the primary means for a user to interact with a cluster. The API server is the only component that communicates directly with the etcd.
kube-scheduler
The kube-scheduler is a control plane component watching newly created pods that have no node assigned yet and assigns them a node to run on.
It assigns the node based on individual and collective resource requirements, hardware/software/policy constraints, and more.
kube-controller-manager
The kube-controller-manager is a control plane component that runs controllers.
To reduce complexity, all controllers are compiled into a single binary and run in a single process.
cloud-controller-manager
The cloud-controller-manager is a control plane component that maps generic representations of resources to actual resources, provided by non-homogeneous cloud providers.
It "glues" the different capabilities, features, and APIs of different providers while maintaining relatively generic constructs internally.
Node components
Servers that perform workloads in Kubernetes (running containers) are called nodes. Nodes may be VMs or physical machines.
Node components are maintaining pods and providing the Kubernetes runtime environment. These components run on every node in the cluster.
kubelet
The kubelet is an agent running on each node and ensuring that containers are running in a pod. It makes sure that containers described in PodSpecs are running and healthy. The agent does not manage any containers that were not created by Kubernetes.
kube-proxy
The kube-proxy is a network proxy running on each node in the cluster. It maintains the network rules on nodes to allow communication to the pods inside the cluster from internal or external connections.
kube-proxy uses either the packet filtering layer of the operating system, if there is one, or forwards the traffic itself if there is none.
Container runtime
Kubernetes is able to manage containers, but is not capable of running them. Therefore, a container runtime is required that is responsible for running containers.
Kubernetes supports several container runtimes like Docker or containerd as well as any implementation of the Kubernetes CRI (Container Runtime Interface).
Kubernetes objects
Kubernetes uses containers to deploy applications, but it also uses additional layers of abstraction to provide scaling, resiliency, and life cycle management features. These abstractions are represented by objects in the Kubernetes API.
Pods
A pod is the smallest and simplest unit in the Kubernetes object model. Containers are not directly assigned to hosts in Kubernetes. Instead, one or multiple containers that are working closely together are bundled in a pod, sharing a unique network address, storage resources and information on how to govern the containers.
Services
A service is an abstraction which defines a logical group of pods that perform the same function and a policy on how to access them. The service provides a stable endpoint (IP address) and acts like a Load Balancer by redirecting requests to the different pods in the service. The service abstraction allows scaling out or replacing dead pods without making changes in the configuration of an application.
By default, services are only available using internally routable IP addresses, but can be exposed publicly.
It can be done either by using the NodePort configuration, which works by opening a static port on each node's external networking interface. Otherwise, it is possible to use the LoadBalancer service, which creates an external Load Balancer at a cloud provider using Kubernetes load-balancer integration.
ReplicaSet
A ReplicaSet contains information about how many pods it can acquire, how many pods it shall maintain, and a pod template specifying the data of new pods to meet the number of replicas criteria. The task of a ReplicaSet is to create and delete pods as needed to reach the desired status.
Each pod within a ReplicaSet can be identified via the metadata.ownerReference field, allowing the ReplicaSet to know the state of each of them. It can then schedule tasks according to the state of the pods.
However, Deployments are a higher-level concept managing ReplicaSets and providing declarative updates to pods with several useful features. It is therefore recommended to use Deployments unless you require some specific customized orchestration.
Deployments
A Deployment is representing a set of identical pods with no individual identities, managed by a deployment controller.
The deployment controller runs multiple replicas of an application as specified in a ReplicaSet. In case any pods fail or become unresponsive, the deployment controller replaces them until the actual state equals the desired state.
StatefulSets
A StatefulSet is able to manage pods like the deployment controller but maintains a sticky identity of each pod. Pods are created from the same base, but are not interchangeable.
The operating pattern of StatefulSet is the same as for any other Controllers. The StatefulSet controller maintains the desired state, defined in a StatefulSet object, by making the necessary update to go from the actual state of a cluster to the desired state.
The unique, number-based name of each pod in the StatefulSet persists, even if a pod is being moved to another node.
DaemonSets
Another type of pod controller is called DaemonSet. It ensures that all (or some) nodes run a copy of a pod. For most use cases, it does not matter where pods are running, but in some cases, it is required that a single pod runs on all nodes. This is useful for aggregating log files, collecting metrics, or running a network storage cluster.
Jobs and CronJobs
Jobs manage a task until it runs to completion. They can run multiple pods in parallel, and are useful for batch-orientated tasks.
CronJobs in Kubernetes work like traditional cron jobs on Linux. They can be used to run tasks at a specific time or interval and may be useful for Jobs such as backups or cleanup tasks.
Volumes
A Volume is a directory that is accessible to containers in a pod. Kubernetes uses its own volumes' abstraction, allowing data to be shared by all containers and remain available until the pod is terminated.
A Kubernetes volume has an explicit lifetime - the same as the pod that encloses it. This means data in a pod will be destroyed when a pod ceases to exist. This also means volumes are not a good solution for storing persistent data.
Persistent volumes
To avoid the constraints of the volume life cycle being tied to the pod life cycle, persistent volumes allow configuring storage resources for a cluster that are independent of the life cycle of a pod.
Once a pod is being terminated, the reclamation policy of the volume determines if the volume is kept until it gets deleted manually or if it is being terminated with the pod.
Going further
- Discover how to deploy your first Kapsule on Scaleway
- Deploy your first Kapsule on Scaleway
- Read the official documentation to learn more about Kubernetes.