Ensuring resiliency with multi-AZ Kubernetes clusters
Kubernetes Kapsule clusters can use Private Networks, providing a default security layer for worker nodes. Furthermore, these clusters can deploy node pools across various Availability Zones (AZs).
Advantages of using multiple Availability Zones
Running a Kubernetes Kapsule cluster across multiple Availability Zones (AZs) enhances high availability and fault tolerance, ensuring your applications remain operational even if one AZ fails due to issues like power outages or natural disasters.
This setup improves disaster recovery, reduces latency by serving users from the nearest AZs, and allows maintenance and upgrades without downtime.
The main advantages of running a Kubernetes Kapsule cluster in multiple AZs are:
-
Disaster recovery and data resilience: By spreading your workload across several AZs, you are setting up a robust disaster recovery strategy. This redundancy ensures your data remains safe, even if one of the AZs faces unexpected issues.
-
Operational flexibility and resource availability: Limitations such as the unavailability of GPU nodes in certain zones (e.g., PAR3) require the creation of an entirely new cluster in a different AZ. With multi-AZ support, you can easily set up pools in various AZs within the same cluster. This flexibility is important, especially when dealing with resource constraints or unavailability in specific zones.
Best practices for a multi-AZ cluster
- We recommend configuring your cluster with at least three nodes spread across at least two different AZs for better reliability and data resiliency.
- Automatically replicate persistent data and storage volumes across multiple AZs to prevent data loss and ensure seamless application performance, even if one zone experiences issues.
- Use topology spread constraints to distribute Pods evenly across different AZs, enhancing the overall availability and resilience of your applications by preventing single points of failure.
- Ensure your load balancers are zone-aware to distribute traffic efficiently across nodes in different AZs, preventing overloading a single zone.
For more information, refer to the official Kubernetes best practices for running clusters in multiple zones documentation.
Limitations
- Kapsule's control plane network access is managed by a Load Balancer in the primary zone of each region. If this zone fails globally, the control plane will be unreachable, even if the cluster spans multiple zones. This limitation also applies to HA Dedicated control planes.
- Persistent volumes are limited to their Availability Zone (AZ). Applications must replicate data across persistent volumes in different AZs to maintain high availability in case of zone failures.
- In "controlled isolation" mode, nodes access the control plane via their public IPs. If two AZs can not communicate (split-brain scenario), nodes will not appear unhealthy from Kubernetes' perspective, but communication between nodes in different AZs will be disrupted. Applications must handle this scenario if they use components across multiple AZs.
- In "full isolation" mode, nodes also use the Public Gateway to access the control plane. If nodes cannot reach the Public Gateway (e.g. because of Private Network failure in an AZ), they will become unhealthy. As there is only one Public Gateway per Private Network, losing the AZ with the Public Gateway results in the loss of all nodes in all private pools across all AZs.
Kubernetes Kapsule infrastructure setup
Prerequisites for setting up a multi-AZ cluster
-
Your cluster must be compatible with, and connected to a Private Network. If it is not, you will need to migrate your cluster following the procedure through the console, API, or Terraform/OpenTofu.
-
Ensure the node types required for your pool are available in your chosen AZs, as not all node types are available in every AZ and stocks might be limited.
Network configuration
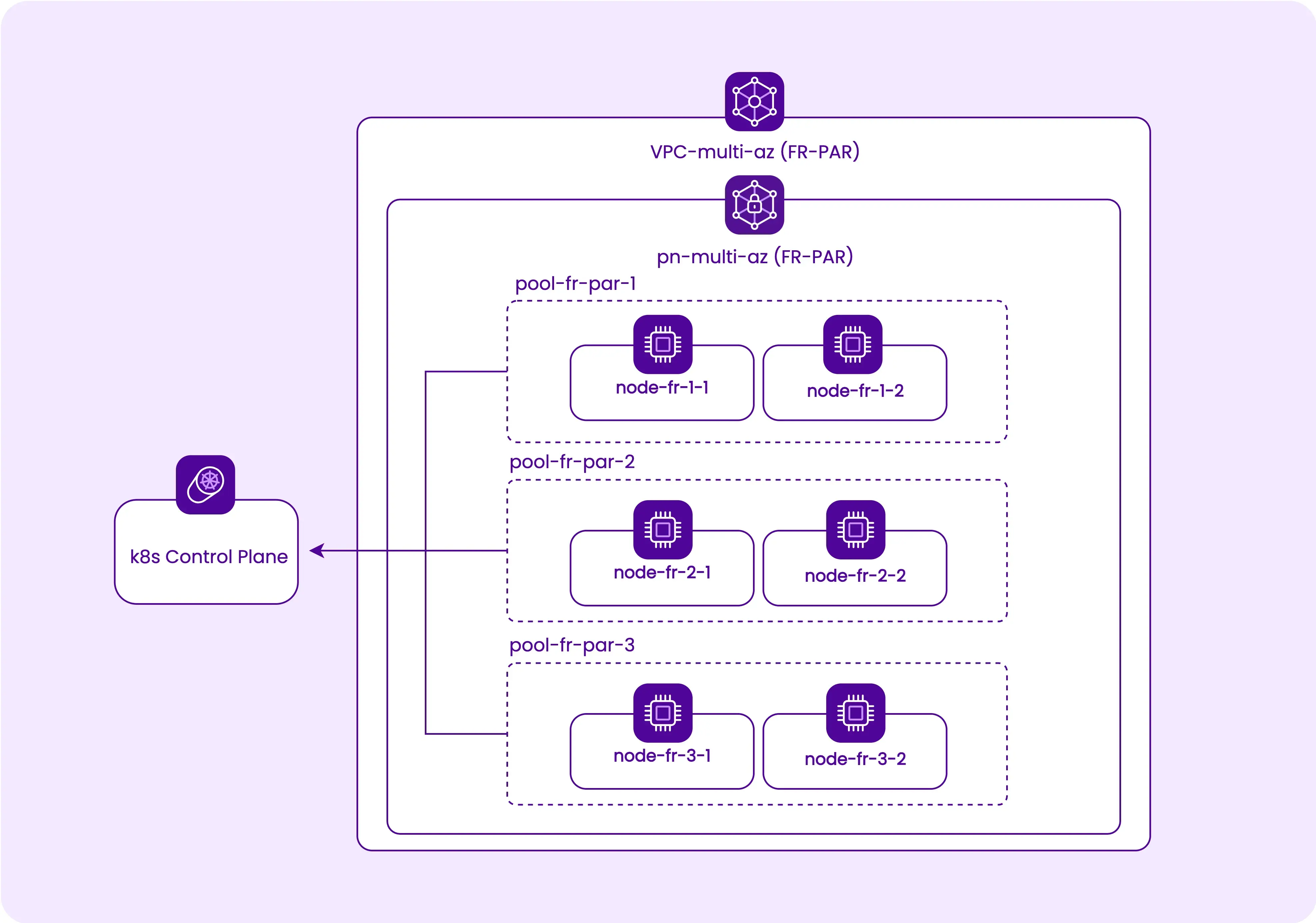
Start by setting up the network for our Kubernetes Kapsule cluster. This setup includes creating a multi-AZ VPC. Using Terraform/OpenTofu, we can manage this infrastructure as shown below:
# Terraform/OpenTofu configuration for Scaleway Kapsule multi-AZ VPC
provider "scaleway" {
#... your Scaleway credentials
}
resource "scaleway_vpc" "vpc_multi_az" {
name = "vpc-multi-az"
tags = ["multi-az"]
}
resource "scaleway_vpc_private_network" "pn_multi_az" {
name = "pn-multi-az"
vpc_id = scaleway_vpc.vpc_multi_az.id
tags = ["multi-az"]
}Cluster and node pool configuration
Once the network is ready, proceed to create the Kubernetes cluster and node pools spanning multiple AZs. Each node pool should correspond to a different AZ for high availability.
# Terraform/OpenTofu configuration for Scaleway Kapsule cluster and node pools
resource "scaleway_k8s_cluster" "kapsule_multi_az" {
name = "kapsule-multi-az"
tags = ["multi-az"]
type = "kapsule"
version = "1.28"
cni = "cilium"
delete_additional_resources = true
autoscaler_config {
ignore_daemonsets_utilization = true
balance_similar_node_groups = true
}
auto_upgrade {
enable = true
maintenance_window_day = "sunday"
maintenance_window_start_hour = 2
}
private_network_id = scaleway_vpc_private_network.pn_multi_az.id
}
resource "scaleway_k8s_pool" "pool-multi-az" {
for_each = {
"fr-par-1" = 1,
"fr-par-2" = 2,
"fr-par-3" = 3
}
name = "pool-${each.key}"
zone = each.key
tags = ["multi-az"]
cluster_id = scaleway_k8s_cluster.kapsule_multi_az.id
node_type = "PRO2-XXS"
size = 2
min_size = 2
max_size = 3
autoscaling = true
autohealing = true
container_runtime = "containerd"
root_volume_size_in_gb = 20
}After applying this Terraform/OpenTofu configuration, the cluster and node pools will be set up across the defined AZs.
Deployments with topologySpreadConstraints
topologySpreadConstraints allow for fine control over how Pods are spread across your Kubernetes cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains.
This approach ensures high availability and resiliency. For more information, refer to the official Kubernetes Pod Topology Spread Constraints documentation.
Here is an example of how you can define topologySpreadConstraints in your deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-resilient-app
spec:
replicas: 6
selector:
matchLabels:
app: resilient-app
template:
metadata:
labels:
app: resilient-app
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: resilient-app
containers:
- name: app
image: my-app-image:latest
#... other settingsIn this example, maxSkew describes the maximum difference between the number of matching Pods in any two topology domains of a given topology type. The topologyKey specifies a key for node labels. For spreading the Pods evenly across zones, use topology.kubernetes.io/zone.
Service with scw-loadbalancer-zone annotation
Scaleway’s load balancer requires specific annotations to control its behavior. In this example, we use the scw-loadbalancer-zone annotation to specify the zone in which the load balancer is deployed.
apiVersion: v1
kind: Service
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/scw-loadbalancer-zone: "fr-par-1"
spec:
selector:
app: resilient-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancerThis service definition creates a load balancer in the "fr-par-1" zone and directs traffic to Pods with the resilient-app label. Learn more about LoadBalancer annotations with our dedicated Scaleway LoadBalancer Annotations documentation.
- Cluster spread over three Availability Zones
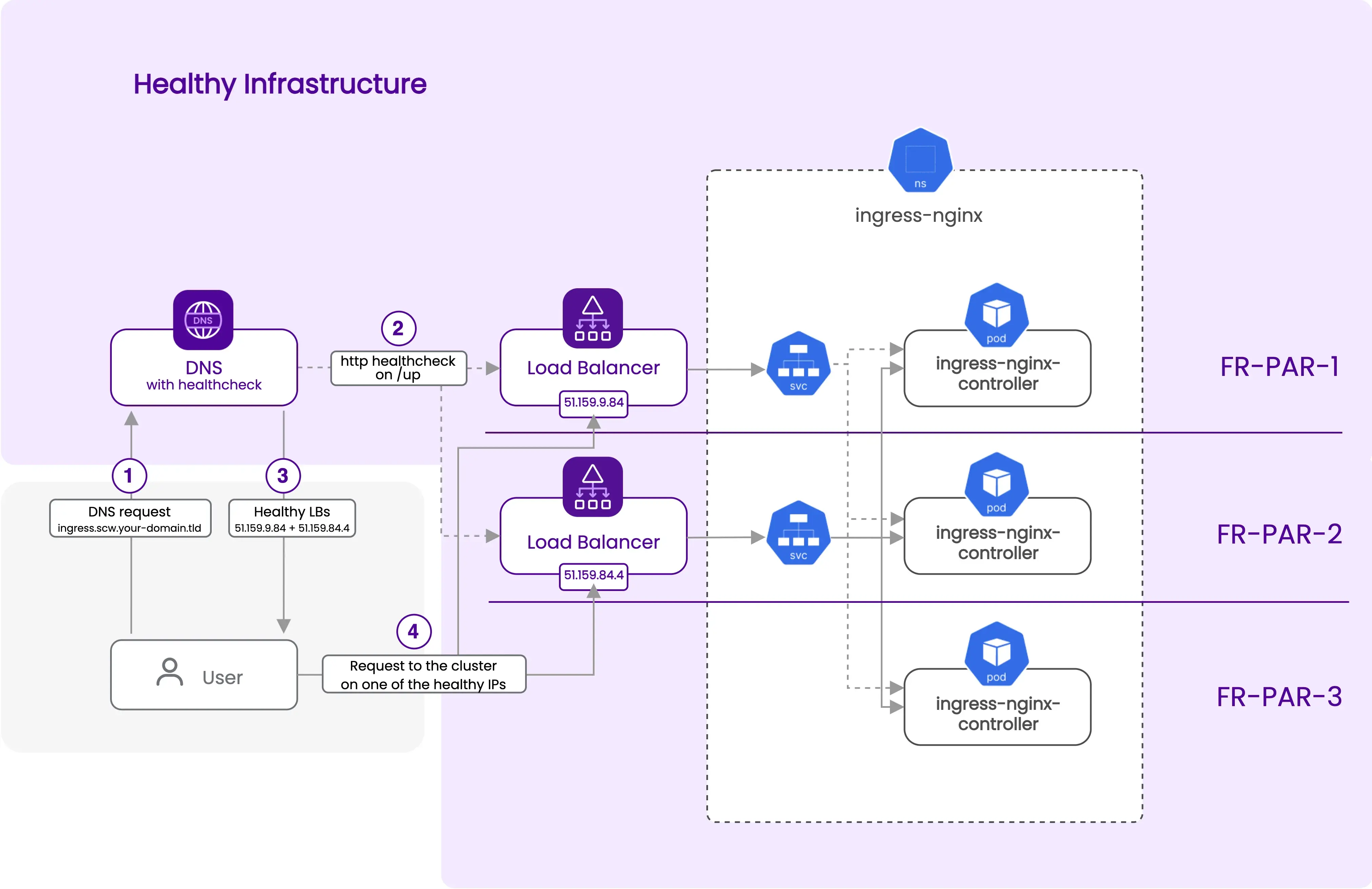
DNS with Dynamic Record (Health Check)
Create a DNS record to direct traffic to active load balancers, assuming you have a domain with an scw zone per the prerequisites. Replace your-domain.tld with your actual domain in the code. For a bare domain, omit the subdomain parameter in the scaleway_domain_zone resource.
The configuration uses http_service to verify the ingress-nginx service's status through the load balancers in both AZs, utilizing the "EXTERNAL-IP" from the Kubernetes services. The "ingress" DNS record in your scw.your-domain.tld domain will point to all healthy load balancer IPs using the "all" strategy. If an AZ fails, the DNS record will auto-update to point only to the healthy load balancer's IP, rerouting traffic to the remaining functional AZs.
- Cluster with an unresponsive Availability Zone
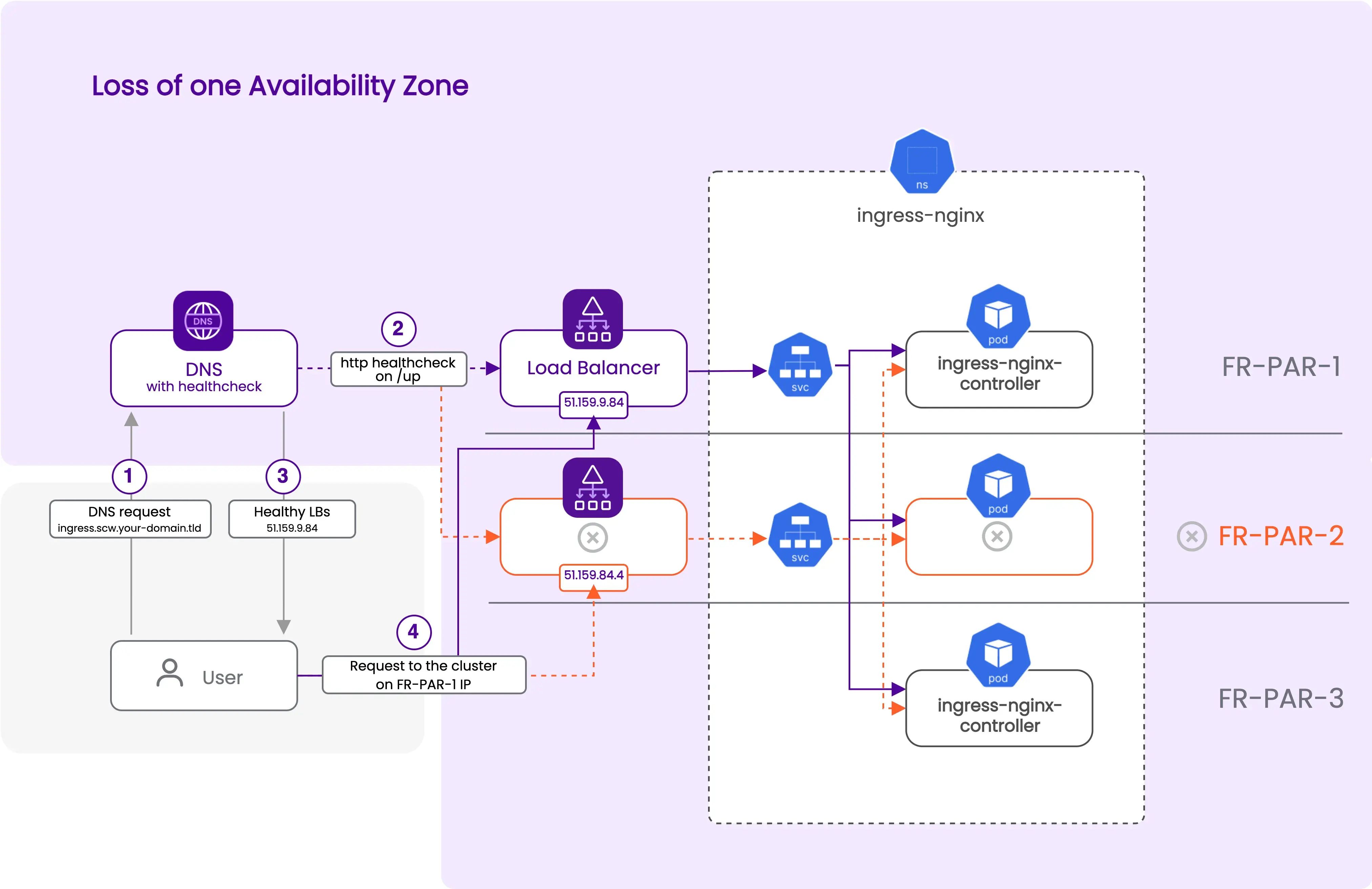
data "scaleway_domain_zone" "multi-az" {
domain = "your-domain.tld"
subdomain = "scw"
}
resource "scaleway_domain_record" "multi-az" {
dns_zone = data.scaleway_domain_zone.multi-az.id
name = "ingress"
type = "A"
data = kubernetes_service.nginx["fr-par-1"].status.0.load_balancer.0.ingress.0.ip
ttl = 60
http_service {
ips = [
kubernetes_service.nginx["fr-par-1"].status.0.load_balancer.0.ingress.0.ip,
kubernetes_service.nginx["fr-par-2"].status.0.load_balancer.0.ingress.0.ip,
]
must_contain = "up"
url = "http://ingress.scw.yourdomain.tld/up"
user_agent = "scw_dns_healthcheck"
strategy = "all"
}
}Storage with VolumeBindingMode
In this final section, the focus will be on stateful applications that require persistent volumes within a multi-Availability Zone (AZ) architecture. A prerequisite is having a default scw-bssd storage class in your cluster, with the volumeBindingMode parameter specifically set to WaitForFirstConsumer.
You can confirm the presence and settings of your storage classes using the kubectl command shown below:
kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
scw-bssd (default) csi.scaleway.com Delete WaitForFirstConsumer true 131m
scw-bssd-retain csi.scaleway.com Retain WaitForFirstConsumer true 131mUsing a storage class with volumeBindingMode set to WaitForFirstConsumer is a requirement when deploying applications across multiple AZs, especially those that rely on persistent volumes. This configuration ensures that volume creation is contingent on the Pod's scheduling, aligning with specific AZ prerequisites.
Creating a volume ahead of this could lead to its arbitrary placement in an AZ, which can cause attachment issues if the Pod is subsequently scheduled in a different AZ. The WaitForFirstConsumer mode ensures that volumes are instantiated in the same AZ as their corresponding node, ensuring distribution across various AZs as Pods are allocated.
This method is an important point to maintain system resilience and operational consistency across multi-AZ deployments.
Additional resources
- Tutorial Deploying a multi-AZ Kubernetes cluster with Terraform/OpenTofu and Kapsule
- Complete Terraform/OpenTofu configuration files to deploy a multi-AZ cluster
- Official Kubernetes best practices for running clusters in multiple zones