Managed Kubernetes service definition
Scaleway Kapsule and Kosmos are managed Kubernetes services. Scaleway's managed Kubernetes service abstracts away the complexities of managing and operating a Kubernetes cluster, enabling developers to focus on application development and deployment while ensuring a reliable and scalable environment for running containerized workloads.
What is a managed Kubernetes service?
In the context of Scaleway, a managed Kubernetes service refers to the Kapsule and Kosmos products. Scaleway handles the management and maintenance of the Kubernetes control plane, along with all the crucial core components required for the proper operation of the Kubernetes cluster.
What components of Kubernetes are managed by Scaleway?
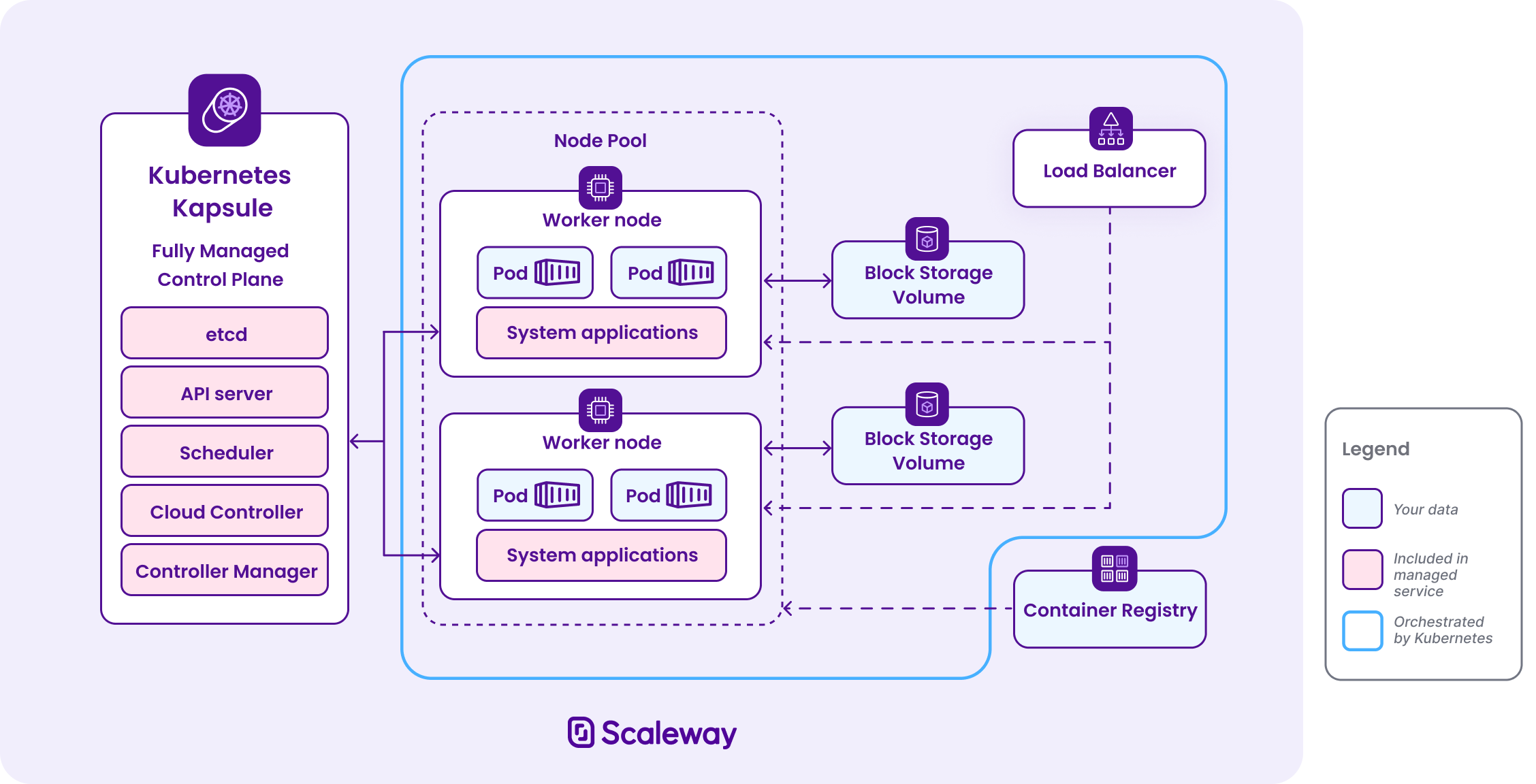
Scaleway manages the Kubernetes control plane (either Kapsule or Kosmos), which consists of various components responsible for managing and maintaining the cluster and its state, and scheduling applications. This includes components such as the control plane itself: etcd, API server, scheduler, cloud controller, and controller manager.
Scaleway takes care of Kubernetes system applications such as CoreDNS, Kubeproxy, Container Networking Interface (CNI), and Container Storage Interface (CSI), which are vital for the optimal functioning of the Kubernetes cluster and its associated resources.
Scaleway is also responsible for node provisioning and providing updates of operating system node images.
Scaleway offers support for the latest minor releases and patches, allowing the user to update them regularly on the cluster using our CLI and console interface.
Furthermore, Scaleway provides information and reminders when older versions reach their end of support, ensuring that users stay informed and upgrade their clusters regularly.
What responsibilities do I have as a user of a managed Kubernetes service?
A user's primary responsibility is to deploy and manage the applications or services that are planned to run on the Kubernetes cluster.
Users are accountable for deploying any resources to the cluster and managing their configurations.
To manage resources effectively, it is essential to use appropriate interfaces like kubectl and the Scaleway Kubernetes console.
Note, however, that the responsibility for managing preinstalled components such as Kubelet at the node or system level shifts to the user when they modify them.
For the security and stability of its clusters, users are also expected to apply patches and security updates regularly. Patch and minor version updates can be directly applied to each cluster through the Scaleway console or CLI to ensure proper functionality. To keep the cluster's nodes up-to-date, it is recommended to set a lifespan limit of 30 days for each node and replace them regularly with the latest version of the underlying OS image. This practice ensures that the cluster operates with the most recent and secure infrastructure.
Who is responsible for Instances, Bare Metal machines, persistent volumes, and Load Balancers attached to the cluster?
When it comes to resources managed exclusively by users through the relevant interfaces like kubectl or the Scaleway Kubernetes console, Scaleway takes on the responsibility.
Kubernetes takes charge of provisioning and orchestrating nodes, persistent volumes, and load balancers that are associated with the cluster.
Scaleway ensures the proper configuration of the cluster to handle these resources and seamlessly integrates them into the Kubernetes environment.
What happens in the event of a cluster failure?
If a cluster failure occurs, Scaleway is able to reset or "restore" the cluster to its default state. However, it is crucial to understand that resetting the cluster does not guarantee immediate perfect functionality.
Certain factors like misconfigurations, applications deployed by the client, or breaking changes in Kubernetes might have contributed to the failure.
In such cases, Scaleway is committed to offering evidence and recommendations through observability alerts or audit logs. These resources can assist the client in investigating and resolving the failure, providing valuable insights into the root cause.